Dynamic optimization#
ECON2125/6012 Lecture 11 Fedor Iskhakov
Announcements & Reminders
Next lecture: revision 1h + questions&answer 1h
Exam practice questions will be posted in the next few days
Plan for this lecture
Dynamic decision problems
Dynamic programming for finite horizon problems
Dynamic programming for infinite horizon problems
Supplementary reading:
Sundaram: chapter 11
Dynamic decision problems#
As before, let’s start with our definition of a general optimization problem
Definition
The general form of the optimization problem is
where:
\(f(x,\theta) \colon \mathbb{R}^N \times \mathbb{R}^K \to \mathbb{R}\) is an objective function
\(x \in \mathbb{R}^N\) are decision/choice variables
\(\theta \in \mathbb{R}^K\) are parameters
\(\mathcal{D}(\theta)\) denotes the admissible set
\(g_i(x,\theta) = 0, \; i\in\{1,\dots,I\}\) where \(g_i \colon \mathbb{R}^N \times \mathbb{R}^K \to \mathbb{R}\), are equality constraints
\(h_j(x,\theta) \le 0, \; j\in\{1,\dots,J\}\) where \(h_j \colon \mathbb{R}^N \times \mathbb{R}^K \to \mathbb{R}\), are inequality constraints
\(V(\theta) \colon \mathbb{R}^K \to \mathbb{R}\) is a value function
Crazy thought
Can we let the objective function include the value function as a component?
Think of an optimization problem that repeats over and over again, for example in time
Value function (as the maximum attainable value) of the next optimization problem may be part of the current optimization problems
The parameters \(\theta\) may be adjusted to link these optimization problems together
Example
Imagine the optimization problem with \(g(x,\theta)= \sum_{t=0}^{\infty}\beta^{t}u(x,\theta)\) where \(b \in (0,1)\) to ensure the infinite sum converges. We can write
Note that the trick in the example above works because \(g(x,\theta)\) is an infinite sum
Among other things this implies that \(x\) is infinite dimension!
Let the parameter \(\theta\) to keep track time, so let \(\theta = (t, s_t)\)
Then it is possible to use the same principle for the optimization problems without infinite sums
Introduce new notation for the value function
Definition: dynamic optimization problems
The general form of the deterministic dynamic optimization problem is
where:
\(f(x,s_t) \colon \mathbb{R}^N \times \mathbb{R}^K \to \mathbb{R}\) is an instantaneous reward function
\(x \in \mathbb{R}^N\) are decision/choice variables
\(s_t \in \mathbb{R}^K\) are state variables
state transitions are given by \(s_{t+1} = g(x,s_t)\) where \(g \colon \mathbb{R}^N \times \mathbb{R}^K \to \mathbb{R}^K\)
\(\mathcal{D}_t(s_t) \subset \mathbb{R}^N\) denotes the admissible set at decision instance (time period) \(t\)
\(\beta \in (0,1)\) is a discount factor
\(V_t(s_t) \colon \mathbb{R}^K \to \mathbb{R}\) is a value function
Denote the set of maximizers of each instantaneous optimization problem as
\(x^\star_t(s_t)\) is called a policy correspondence or policy function
State space \(s_t\) is of primary importance for the economic interpretation of the problem: it encompasses all the information that the decision maker conditions their decisions on
Has to be carefully founded in economic theory and common sense
Similarly the transition function \(g(x,s_t)\) reflects the exact beliefs of the decision maker about how the future state is determined and has direct implications for the optimal decisions
Note
In the formulation above, as seen from transition function \(g(x,s_t)\), we implicitly assume that the history of states from some initial time period \(t_0\) is not taken into account. Decision problems where only the current state is relevant for the future are called Markovian decision problems
Dynamic programming and Bellman principle of optimality#
An optimal policy has a property that whatever the initial state and initial decision are, the remaining decisions must constitute an optimal policy with regard to the state resulting from the first decision.
📖 Bellman, 1957 “Dynamic Programming”
Main idea
Breaking the problem into sequence of small problems
Dynamic programming is recursive method for solving sequential decision problems
📖 Rust 2006, New Palgrave Dictionary of Economics
In computer science the meaning of the term is broader: DP is a general algorithm design technique for solving problems with overlapping sub-problems
Thus, the sequential decision problem is broken into current decision and the future decisions problems, and solved recursively
The solution can be computed through backward induction which is the process of solving a sequential decision problem from the later periods to the earlier ones, this is the main algorithm used in dynamic programming (DP)
Embodiment of the recursive way of modeling sequential decisions is Bellman equation
Definition
Bellman equation is a functional equation in an unknown function \(V(\cdot)\) which embodies a dynamic optimization problem and has the form
expectation \(\mathbb{E}\{\cdot\}\) is taken over the distribution of the next period state conditional on current state and decision when the state transitions are given by a stochastic process
the optimal choices (policy correspondence) are revealed along the solution of the Bellman equation as decisions which solve the maximization problem in the right hand side, i.e.
DP is a the main tool in analyzing modern micro and macto economic models
DP provides a framework to study decision making over time and under uncertainty and can accommodate:
learning and human capital formation
wealth accumulation
health dynamics
strategic interactions between agents (game theory)
market interactions (equilibrium theory)
etc
Many important problems and economic models are analyzed and solved using dynamic programming:
Dynamic models of labor supply
Job search
Human capital accumulation
Health process, insurance and long term care
Consumption/savings choices
Durable consumption
Growth models
Heterogeneous agents models
Overlapping generation models
Origin of the term Dynamic Programming
The 1950’s were not good years for mathematical research. We had a very interesting gentleman in Washington named Wilson. He was Secretary of Defence, and he actually had a pathological fear and hatred of the word “research”.
I’m not using the term lightly; I’m using it precisely. His face would suffuse, he would turn red, and he would get violent if people used the term, research, in his presence. You can imagine how he felt, then, about the term, mathematical.
Hence, I felt I had to do something to shield Wilson and the Air Force from the fact that I was really doing mathematics inside the RAND Corporation.
What title, what name, could I choose?
In the first place, I was interested in planning, in decision-making, in thinking. But planning, is not a good word for various reasons. I decided therefore to use the word, “programming”.
I wanted to get across the idea that this was dynamic, this was multistage, this was time-varying.
I thought, let’s kill two birds with one stone. Let’s take a word which has an absolutely precise meaning, namely dynamic, in the classical physical sense.
It also has a very interesting property as an adjective, and that is it’s impossible to use the word, dynamic, in the pejorative sense.
Thus, I thought dynamic programming was a good name. It was something not even a Congressman could object to. So I used it as an umbrella for my activities.
📖 Bellman’s autobiography “The Eye of the Hurricane”
Finite and infinite horizon problems#
Although dynamic programming primarily deals with infinite horizon problems, it can also be applied to the finite horizon problems where \(T < \infty\)
Terms backwards induction and dynamic programming are associated by many authors respectively with finite and infinite horizon problems
Our definition of a dynamic optimization problem contains elements of both finite and infinite horizon problem setup, and needs more detail
Finite horizon problems
Time is discrete and finite, \(t \in \{0,1,\dots,T\}\) where \(T < \infty\)
Parameter vector \(\theta\) indeed contains \(t\) such that the value and policy functions along with other elements of the model do depend on \(t\), i.e. may differ between time periods
“Bellman equation” is a (common!) misuse of the term, because with time subscripts for the value function, it is not a functional equation any more
However, the term “Bellman equation” is still used for the finite horizon problems to denote the following expression:
Period \(t=T\) is referred to as the terminal period, and the value function at this period is called the terminal value function
Because there is no next period in the terminal period, \(V_{T+1}(s_{T+1}) = 0\) for all \(s_T\), giving the expression for the Bellman equation above
Infinite horizon problems
Time is discrete and infinite, \(t \in \{0,1,\dots,\infty\}\), sometimes denoted as \(T = \infty\)
Parameter vector \(\theta\) does not contain \(t\) and so the value and policy functions can not depend on \(t\), and so other elements of the model
In other words, the solution of the model in this case has to be time invariant
Bellman equation is a proper functional equation, which together with the policy function, describes the optimal decision rule in the long term. In some sense, the solution to the infinite dimensional problem is one pair \((V(s), x^\star(s))\), whereas in the general setup both elements of the solution are tuples
Let’s look at a particular example
Inventory management in finite horizon#
Example
The manager of a store has to order the stock of a product from a wholesales company as the inventory is depleted by sales.
The manager can order any amount of the product at any time, but there is a fixed cost \(c\) of ordering any amount of new inventory. The manager can also store the product in the warehouse, but there is a cost \(r\) of storing one unit of the product.
The store receives a profit \(p\) for each unit of the product sold and so the manager’s goal is to maximize the net profit over the time horizon \(t=0,\dots,T\).
We have:
\(p\) is the profit per one unit of sold good
\(c\) is the fixed cost of ordering any amount of new inventory
\(r\) is the cost of storing one unit of good
Let’s introduce some notation:
\(x_t\ge 0\) is inventory at period \(t\), let it be measured in discrete units
\(d_t\ge 0\) is potentially stochastic demand at period \(t\)
\(q_t\ge 0\) is the order of new inventory
Then:
the sales in period \(t\) are given by \(\min\{x_t,d_t\}\)
inventory to be stored till next period is given by
profit in period \(t\) is given by
assuming all \(q_t \ge 0\), we have \(\mathcal{D}_t = \{q_t \colon q_t \ge 0 \}\)
to make the set of feasible choices compact we may assume a maximum level of inventory \(x_{\max}\), and so \(\mathcal{D}_t = \{q_t \colon 0 \le q_t \le x_{\max} \}\)
The expected profit maximizing problem is given by
or in the case of stochastic with the expectation over its distribution
where \(\beta\) is discount factor
Note
The maximization problem is formulated with respect to a series of choices \(\{q_t\}_{t=0}^T\) which is a tuple of \(T+1\) elements, one for each period \(t=0,\dots,T\). Given that in each period the parameters of the optimization problem change, at least potentially, we will keep in mind that the elements of this series should be thought of as dependent on the corresponding parameters, as in the theorem of maximum. In this case the relevant parameter is the state variable \(s_t\), and thus we will write \(\{q_t(s_t)\}_{t=0}^T\).
Bellman equation for the problem
Decisions: \(q_t\), how much new inventory to order
What is important for the inventory decision at time period \(t\)?
timing of the decision making process: (beginning of period) - current inventory - demand - (choice) order - stored inventory - storage during the period \(\rightarrow\) (beginning of the next of period)
instanteneous utility (profit) contains \(x_t\) and \(d_t\)
So, both \(x_t\) and \(d_t\) are taken into account for the new order to be made, forming the state space
Therefore, for \(t<T\), we can write the following Bellman equation
The expectation in the Bellman equation is taken over the distribution of the next period demand \(d_{t+1}\), which we assume is independent of any other variables and across time (idiosyncratic), thus the expectation is not conditioned on current state and choice variable \((x_t,d_t,q_t)\) (although in general it would be)
Expectation can be written as an integral over the distribution of demand \(F(d)\), but since inventory is discrete it’s natural to assume demand is as well Then the integral then transforms into a sum over the possible value of demand, weighted by their probabilities \(pr(d)\)
Because the problem is set in finite time, for \(t=T\) the Bellman takes the simple form without the next period value
This part of the Bellman equation can be solved immediately: it is obvious that making any order in the terminal period only brings on the fixed cost of order, and therefore the optimal choice is \(q_T^\star = 0\), leading to
Solving the deterministic version
Let \(d_t =d\) be fixed and constant across time. How does the Bellman equation change?
In the deterministic case with fixed \(d\), it can be simply dropped from the state space, and the Bellman equation can be simplified to
Backwards induction algorithm
Solver for the finite horizon dynamic programming problems
Start at \(t=T\), assume \(V_T(s_T)=0\)
Solve Bellman equation at \(t\) using the already known \(V_{t+1}(s_{t+1})\)
Record optimal choice (policy function) \(x^\star_t(s_t)\) and the value function \(V_t(s_t)\)
While \(t>1\), decrease \(t\) by 1 and return to step 2, otherwise stop
We already solved the model in terminal period above and determined that \(q_T^\star = 0\), so we can start at \(t=T-1\) and solve the Bellman equation for \(V_{T-1}(x_{T-1})\) and find \(q_{T-1}^\star(x_{T-1})\). Because the choice variable \(q_{T-1}\) is discrete (takes values from a finite/countable set), there is no FOCs, and we simply compare the value of the objective at different values of the choice variable, and choose the maximum one.
Let’s do this numerically!
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = [12, 8]
class inventory_model:
'''Small class to hold model fundamentals and its solution'''
def __init__(self,label='noname',
max_inventory=10, # upper bound on the state space
c = 3.2, # fixed cost of order
p = 2.5, # profit per unit of good
r = 0.5, # storage cost per unit of good
β = 0.95, # discount factor
dp = 0.5, # parameter in geometric distribution of demand
demand = 4 # fixed demand
):
'''Create model with default parameters'''
self.label=label # label for the model instance
self.c, self.p, self.r, self.β, self.dp= c, p, r, β, dp
self.demand = demand
# created dependent attributes (it would be better to have them updated when underlying parameters change)
self.n = max_inventory+1 # number of inventory levels
self.upper = max_inventory # upper boundary on inventory
self.x = np.arange(self.n) # all possible values of inventory and demand (state space)
def __repr__(self):
'''String representation of the model'''
return 'Inventory model labeled "{}"\nParamters (c,p,r,β) = ({},{},{},{})\nDemand={}\nUpper bound on inventory {}' \
.format (self.label,self.c,self.p,self.r,self.β,self.demand,self.upper)
def sales(self,x,d):
'''Sales in given period'''
return np.minimum(x,d)
def next_x(self,x,d,q):
'''Inventory to be stored, becomes next period state'''
return x - self.sales(x,d) + q
def profit(self,x,d,q):
'''Profit in given period'''
return self.p * self.sales(x,d) - self.r * self.next_x(x,d,q) - self.c * (q>0)
def demand_pr(self,plot=False):
'''Computes stochastic demand probs'''
k = np.arange(self.n) # all possible values of demand
pr = (1-self.dp)**k *self.dp
pr[-1] = 1 - pr[:-1].sum() # update last prob to ensure sum=1
if plot:
plt.step(self.x,pr,where='mid')
plt.title('Distribution of demand')
plt.show()
return pr
model=inventory_model(label='test')
print(model)
Inventory model labeled "test"
Paramters (c,p,r,β) = (3.2,2.5,0.5,0.95)
Demand=4
Upper bound on inventory 10
Show code cell source
def bellman(m,v0):
'''Bellman equation for inventory model
Inputs: model object
next period value function
'''
# create the grid of choices (same as x), column-vector
q = m.x[:,np.newaxis]
# compute current period profit (relying on numpy broadcasting to get the matrix with choices in rows)
p = m.profit(m.x,m.demand,q)
# indexes for next period value with extrapolation using last value
i = np.minimum(m.next_x(m.x,m.demand,q),m.upper)
# compute the Bellman maximand
vm = p + m.β*v0[i]
# find max and argmax
v1 = np.amax(vm,axis=0) # maximum in every column
q1 = np.argmax(vm,axis=0) # arg-maximum in every column = order volume
return v1, q1
def solver_backwards_induction(m,T=10,verbose=False):
'''Backwards induction solver for the finite horizon case'''
# solution is time dependent
m.value = np.zeros((m.n,T))
m.policy = np.zeros((m.n,T))
# main DP loop (from T to 1)
for t in range(T,0,-1):
if verbose:
print('Time period %d\n'%t)
j = t-1 # index of value and policy functions for period t
if t==T:
# terminal period: ordering zero is optimal
m.value[:,j] = m.profit(m.x,m.demand,np.zeros(m.n))
m.policy[:,j] = np.zeros(m.n)
else:
# all other periods
m.value[:,j], m.policy[:,j] = bellman(m,m.value[:,j+1]) # next period to Bellman
if verbose:
print(m.value,'\n')
# return model with updated value and policy functions
return m
model = inventory_model(label='illustration')
model=solver_backwards_induction(model,T=5,verbose=True)
print('Optimal policy:\n',model.policy)
Time period 5
[[ 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 2.5]
[ 0. 0. 0. 0. 5. ]
[ 0. 0. 0. 0. 7.5]
[ 0. 0. 0. 0. 10. ]
[ 0. 0. 0. 0. 9.5]
[ 0. 0. 0. 0. 9. ]
[ 0. 0. 0. 0. 8.5]
[ 0. 0. 0. 0. 8. ]
[ 0. 0. 0. 0. 7.5]
[ 0. 0. 0. 0. 7. ]]
Time period 4
[[ 0. 0. 0. 4.3 0. ]
[ 0. 0. 0. 6.8 2.5 ]
[ 0. 0. 0. 9.3 5. ]
[ 0. 0. 0. 11.8 7.5 ]
[ 0. 0. 0. 14.3 10. ]
[ 0. 0. 0. 14.3 9.5 ]
[ 0. 0. 0. 14.3 9. ]
[ 0. 0. 0. 15.625 8.5 ]
[ 0. 0. 0. 17.5 8. ]
[ 0. 0. 0. 16.525 7.5 ]
[ 0. 0. 0. 15.55 7. ]]
Time period 3
[[ 0. 0. 9.425 4.3 0. ]
[ 0. 0. 11.925 6.8 2.5 ]
[ 0. 0. 14.425 9.3 5. ]
[ 0. 0. 16.925 11.8 7.5 ]
[ 0. 0. 19.425 14.3 10. ]
[ 0. 0. 19.425 14.3 9.5 ]
[ 0. 0. 19.425 14.3 9. ]
[ 0. 0. 19.71 15.625 8.5 ]
[ 0. 0. 21.585 17.5 8. ]
[ 0. 0. 21.085 16.525 7.5 ]
[ 0. 0. 20.585 15.55 7. ]]
Time period 2
[[ 0. 13.30575 9.425 4.3 0. ]
[ 0. 15.80575 11.925 6.8 2.5 ]
[ 0. 18.30575 14.425 9.3 5. ]
[ 0. 20.80575 16.925 11.8 7.5 ]
[ 0. 23.30575 19.425 14.3 10. ]
[ 0. 23.30575 19.425 14.3 9.5 ]
[ 0. 23.30575 19.425 14.3 9. ]
[ 0. 24.57875 19.71 15.625 8.5 ]
[ 0. 26.45375 21.585 17.5 8. ]
[ 0. 25.95375 21.085 16.525 7.5 ]
[ 0. 25.45375 20.585 15.55 7. ]]
Time period 1
[[17.9310625 13.30575 9.425 4.3 0. ]
[20.4310625 15.80575 11.925 6.8 2.5 ]
[22.9310625 18.30575 14.425 9.3 5. ]
[25.4310625 20.80575 16.925 11.8 7.5 ]
[27.9310625 23.30575 19.425 14.3 10. ]
[27.9310625 23.30575 19.425 14.3 9.5 ]
[27.9310625 23.30575 19.425 14.3 9. ]
[28.2654625 24.57875 19.71 15.625 8.5 ]
[30.1404625 26.45375 21.585 17.5 8. ]
[29.6404625 25.95375 21.085 16.525 7.5 ]
[29.1404625 25.45375 20.585 15.55 7. ]]
Optimal policy:
[[8. 8. 8. 4. 0.]
[8. 8. 8. 4. 0.]
[8. 8. 8. 4. 0.]
[8. 8. 8. 4. 0.]
[8. 8. 8. 4. 0.]
[7. 7. 7. 3. 0.]
[6. 6. 6. 2. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
Show code cell source
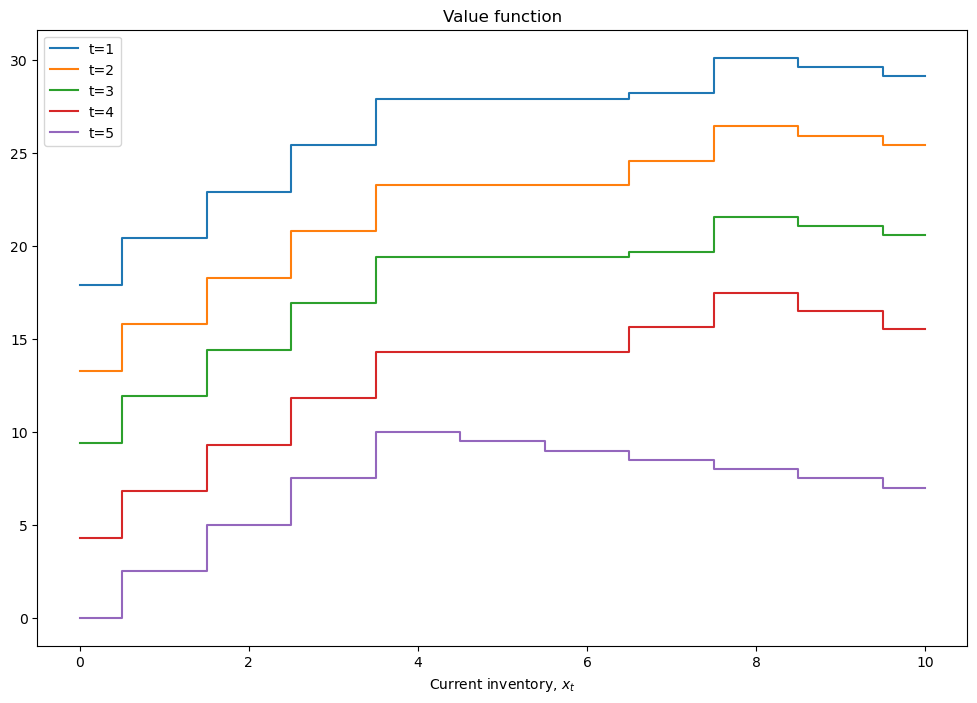
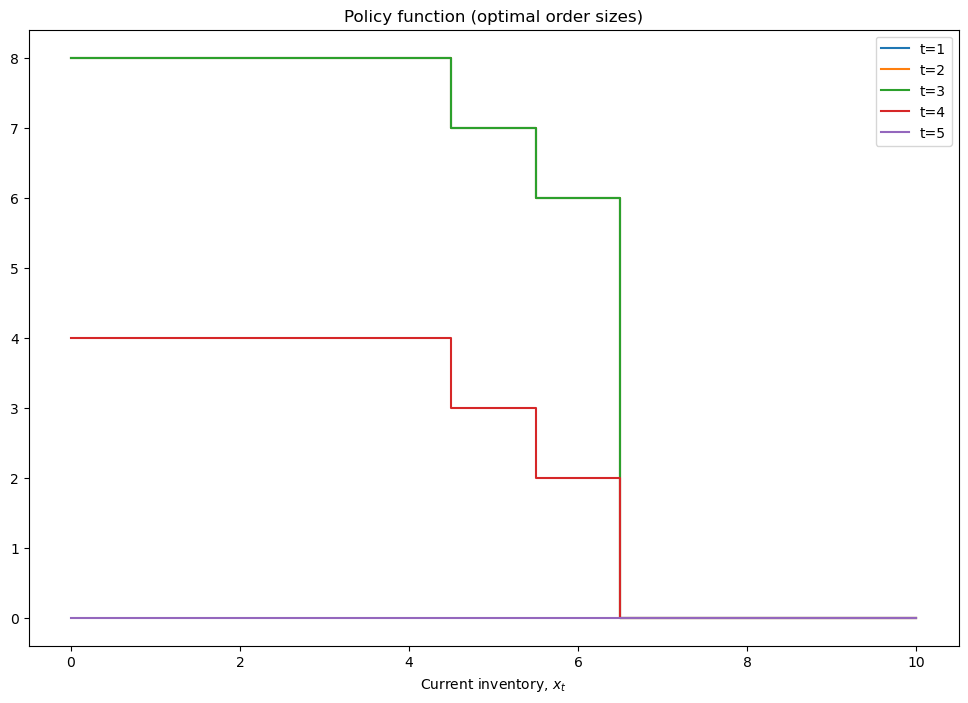
def plot_solution(model):
plt.step(model.x,model.value,where='mid')
plt.xlabel(r'Current inventory, $x_t$')
plt.legend([f't={i+1}' for i in range(model.value.shape[1])])
plt.title('Value function')
plt.show()
plt.step(model.x,model.policy,where='mid')
plt.xlabel(r'Current inventory, $x_t$')
plt.legend([f't={i+1}' for i in range(model.policy.shape[1])])
plt.title('Policy function (optimal order sizes)')
plt.show()
plot_solution(model)
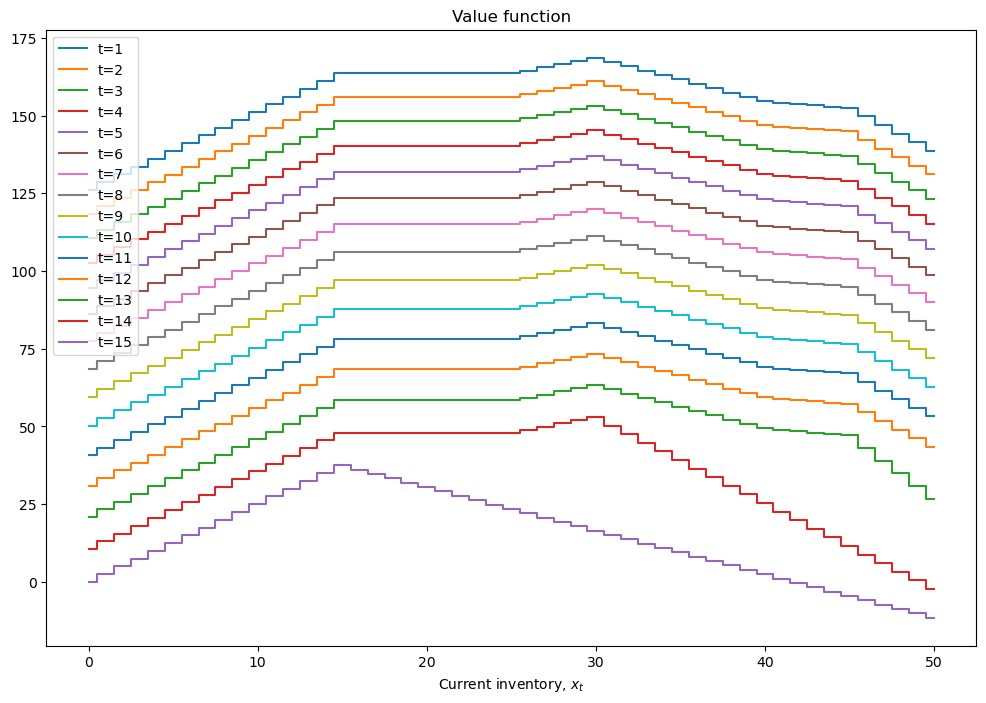
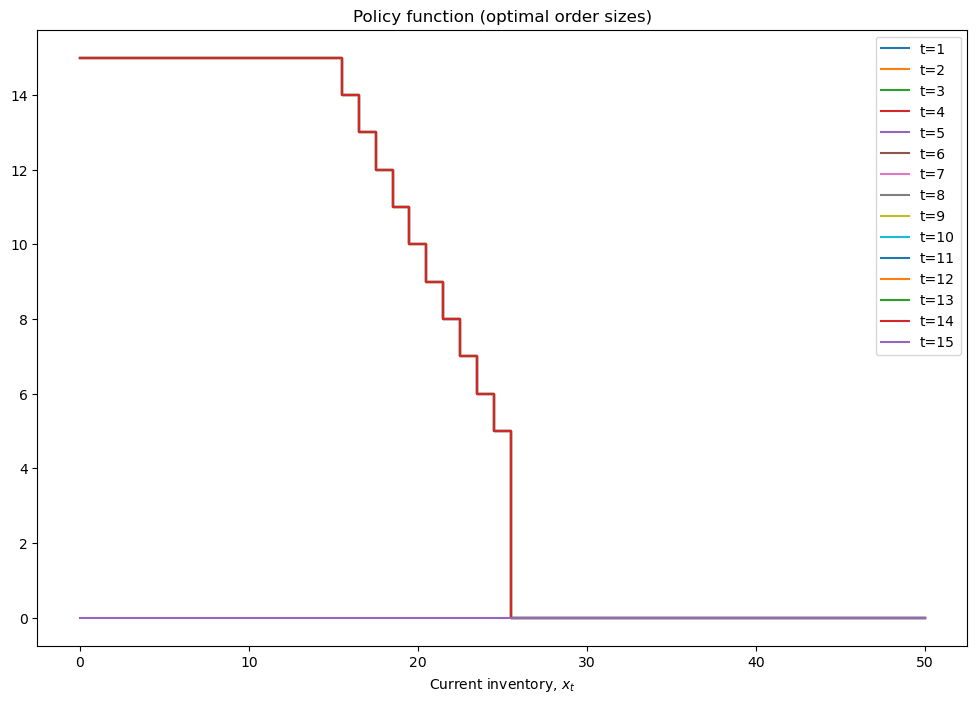
mod = inventory_model(label='production',max_inventory=50)
mod.demand = 15
mod.c = 5
mod.p = 2.5
mod.r = 1.4
mod.β = 0.975
mod = solver_backwards_induction(mod,T=15)
plot_solution(mod)
Note
Do we need to use backwards induction for the model above?
we could set it as a multivariate optimization w.r.t. the vector \((q_0,\dots,q_T)\)
the objective can be rewritten by plugging in the maximand of in period \(t+1\) into the equation for period \(t\) using the transition equation \(g(\cdot)\)
Thus any deterministic infinite horizon problem can be written and solved as a standard constrained optimization problem
But as soon as we introduce uncertainty, this approach breaks down:
there is no transition equation \(g(\cdot)\) to plug in, instead there is a transition probability and an expectation
the optimization problem in each period depends on the paramters (state variables) in a non-trivial way, and has to be solved separately for each value of parameters
Infinite horizon and stochastic dynamic optimization problems#
\(T = \infty\)
subscripts \(t\) can be dropped
solution of the model \(V(s), x^\star(s)\) is time invariant
Bellman equation is a proper functional equation where the value function \(V(s)\) is an unknown
In infinite horizon the dynamic optimization problem
where \(s'\) is the next period state, becomes a fixed point problem of a Bellman operator, i.e. the problem of solving a functional equation.
Definition
Let \(B(S)\) denote a set of all bounded real-valued functions on a set \(S \subset \mathbb{R}^K\).
Bellman operator is a mapping from \(B(S)\) to itself defined as
where:
\(f(x,s) \colon \mathbb{R}^N \times S \to \mathbb{R}\) is an instantaneous reward function
\(x \in \mathbb{R}^N\) are decision/choice variables
\(s \in S \subset \mathbb{R}^K\) are state variables
state transitions are given by \(s' = g(x,s)\) where \(g \colon \mathbb{R}^N \times S \to S\)
\(\mathcal{D}(s) \subset \mathbb{R}^N\) denotes the admissible set
\(\beta \in (0,1)\) is a discount factor
\(V(s) \colon S \to \mathbb{R}\) is a value function
Solution of the Bellman equation is given by a fixed point of the Bellman operator, i.e. such function \(V(\cdot)\) which is mapped to itself by the Bellman operator, and the corresponding policy function
Theory of dynamic programming#
Definition: contraction mapping
Let \((S,\rho)\) be a complete metric space, i.e. a metric space where every Cauchy sequence converges to a point in \(S\).
Let \(T: S \rightarrow S\) denote an operator mapping \(S\) to itself. \(T\) is called a contraction on \(S\) with modulus \(\lambda\) if \(0 \le \lambda < 1\) and
Contraction mapping brings points in its domain “closer” to each other!
Example
What is the value of annuity \(V\) paying regular payments \(c\) forever?
Let \(r\) be the interest rate, then the value of annuity is given by
Equivalently with \(\beta = \frac{1}{1+r}\)
Can reformulate recursively (as “Bellman equation” without choice)
with the corresponding “Bellman operator”
Is \(T(V)\) a contraction?
Yes as long as long as \(\beta < 1\)!
contraction mapping under Euclidean norm
modulus of the contraction is \(\beta\)
Contractions are invaluable because of uniqueness of their fixed point and a surefire algorithm to compute them
Banach contraction mapping theorem (fixed point theorem)
Let \((S,\rho)\) be a complete metric space with a contraction mapping \(T: S \rightarrow S\). Then
\(T\) admits a unique fixed-point \(V^{\star} \in S \colon T(V^{\star}) = V^{\star}\)
\(V^{\star}\) can be found by repeated application of the operator \(T\), i.e. \(T^n(V) \rightarrow V^{\star}\) as \(n\rightarrow \infty\)
In other words, the fixed point can be found by successive approximations from any starting point \(\rightarrow\) commonly known in economics as value function iterations (VFI) algorithm
Value function iterations (VFI) algorithm
Start with a guess for value function \(V_0\), \(i=0\)
Apply Bellman operator to \(V_i\) and increment \(i\)
Repeat until convergence, i.e. \(\| V_{i+1}-V_i \|<\epsilon\) for some small $\e
Show code cell content
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
class annuity():
def __init__(self,c=1,beta=.9):
self.c = c # Annual payment
self.beta = beta # Discount factor
self.analytic = c/(1-beta) # compute analytic solution right away
def bellman(self,V):
'''Bellman equation'''
return self.c + self.beta*V
def solve(self, maxiter = 1000, tol=1e-4, verbose=False):
'''Solves the model using successive approximations'''
if verbose: print('{:<4} {:>15} {:>15}'.format('Iter','Value','Error'))
V0=0
for i in range(maxiter):
V1=self.bellman(V0)
if verbose: print('{:<4d} {:>15.8f} {:>15.8f}'.format(i,V1,V1-self.analytic))
if abs(V1-V0) < tol:
break
V0=V1
else: # when i went up to maxiter
print('No convergence: maximum number of iterations achieved!')
return V1
a = annuity(c=10,beta=0.92)
a.solve(verbose=True)
print('Numeric solution is ',a.solve())
Iter Value Error
0 10.00000000 -115.00000000
1 19.20000000 -105.80000000
2 27.66400000 -97.33600000
3 35.45088000 -89.54912000
4 42.61480960 -82.38519040
5 49.20562483 -75.79437517
6 55.26917485 -69.73082515
7 60.84764086 -64.15235914
8 65.97982959 -59.02017041
9 70.70144322 -54.29855678
10 75.04532776 -49.95467224
11 79.04170154 -45.95829846
12 82.71836542 -42.28163458
13 86.10089619 -38.89910381
14 89.21282449 -35.78717551
15 92.07579853 -32.92420147
16 94.70973465 -30.29026535
17 97.13295588 -27.86704412
18 99.36231941 -25.63768059
19 101.41333385 -23.58666615
20 103.30026715 -21.69973285
21 105.03624577 -19.96375423
22 106.63334611 -18.36665389
23 108.10267842 -16.89732158
24 109.45446415 -15.54553585
25 110.69810702 -14.30189298
26 111.84225846 -13.15774154
27 112.89487778 -12.10512222
28 113.86328756 -11.13671244
29 114.75422455 -10.24577545
30 115.57388659 -9.42611341
31 116.32797566 -8.67202434
32 117.02173761 -7.97826239
33 117.65999860 -7.34000140
34 118.24719871 -6.75280129
35 118.78742281 -6.21257719
36 119.28442899 -5.71557101
37 119.74167467 -5.25832533
38 120.16234070 -4.83765930
39 120.54935344 -4.45064656
40 120.90540517 -4.09459483
41 121.23297275 -3.76702725
42 121.53433493 -3.46566507
43 121.81158814 -3.18841186
44 122.06666109 -2.93333891
45 122.30132820 -2.69867180
46 122.51722194 -2.48277806
47 122.71584419 -2.28415581
48 122.89857665 -2.10142335
49 123.06669052 -1.93330948
50 123.22135528 -1.77864472
51 123.36364686 -1.63635314
52 123.49455511 -1.50544489
53 123.61499070 -1.38500930
54 123.72579144 -1.27420856
55 123.82772813 -1.17227187
56 123.92150988 -1.07849012
57 124.00778909 -0.99221091
58 124.08716596 -0.91283404
59 124.16019268 -0.83980732
60 124.22737727 -0.77262273
61 124.28918709 -0.71081291
62 124.34605212 -0.65394788
63 124.39836795 -0.60163205
64 124.44649851 -0.55350149
65 124.49077863 -0.50922137
66 124.53151634 -0.46848366
67 124.56899504 -0.43100496
68 124.60347543 -0.39652457
69 124.63519740 -0.36480260
70 124.66438161 -0.33561839
71 124.69123108 -0.30876892
72 124.71593259 -0.28406741
73 124.73865798 -0.26134202
74 124.75956535 -0.24043465
75 124.77880012 -0.22119988
76 124.79649611 -0.20350389
77 124.81277642 -0.18722358
78 124.82775431 -0.17224569
79 124.84153396 -0.15846604
80 124.85421124 -0.14578876
81 124.86587435 -0.13412565
82 124.87660440 -0.12339560
83 124.88647605 -0.11352395
84 124.89555796 -0.10444204
85 124.90391333 -0.09608667
86 124.91160026 -0.08839974
87 124.91867224 -0.08132776
88 124.92517846 -0.07482154
89 124.93116418 -0.06883582
90 124.93667105 -0.06332895
91 124.94173736 -0.05826264
92 124.94639837 -0.05360163
93 124.95068650 -0.04931350
94 124.95463158 -0.04536842
95 124.95826106 -0.04173894
96 124.96160017 -0.03839983
97 124.96467216 -0.03532784
98 124.96749839 -0.03250161
99 124.97009852 -0.02990148
100 124.97249063 -0.02750937
101 124.97469138 -0.02530862
102 124.97671607 -0.02328393
103 124.97857879 -0.02142121
104 124.98029248 -0.01970752
105 124.98186909 -0.01813091
106 124.98331956 -0.01668044
107 124.98465399 -0.01534601
108 124.98588167 -0.01411833
109 124.98701114 -0.01298886
110 124.98805025 -0.01194975
111 124.98900623 -0.01099377
112 124.98988573 -0.01011427
113 124.99069487 -0.00930513
114 124.99143928 -0.00856072
115 124.99212414 -0.00787586
116 124.99275421 -0.00724579
117 124.99333387 -0.00666613
118 124.99386716 -0.00613284
119 124.99435779 -0.00564221
120 124.99480917 -0.00519083
121 124.99522443 -0.00477557
122 124.99560648 -0.00439352
123 124.99595796 -0.00404204
124 124.99628132 -0.00371868
125 124.99657882 -0.00342118
126 124.99685251 -0.00314749
127 124.99710431 -0.00289569
128 124.99733597 -0.00266403
129 124.99754909 -0.00245091
130 124.99774516 -0.00225484
131 124.99792555 -0.00207445
132 124.99809150 -0.00190850
133 124.99824418 -0.00175582
134 124.99838465 -0.00161535
135 124.99851388 -0.00148612
136 124.99863277 -0.00136723
137 124.99874215 -0.00125785
138 124.99884277 -0.00115723
139 124.99893535 -0.00106465
Numeric solution is 124.9989353524933
Answer by the geometric series formula, assuming \(\beta<1\)
print(f'Analytic solution is {a.analytic}')
Analytic solution is 125.00000000000006
When is Bellman operator a contraction?
Bellman operator \(T: U \rightarrow U\) from functional space \(U\) to itself
metric space \((U,d_{\infty})\) with uniform/infinity/sup norm (max abs distance between functions over their domain)
Blackwell sufficient conditions for contraction
Let \(X \subseteq \mathbb{R}^n\) and \(B(x)\) be the space of bounded functions \(f: X \rightarrow \mathbb{R}\) defined on \(X\). Suppose that \(T: B(X) \rightarrow B(X)\) is an operator satisfying the following conditions:
(monotonicity) For any \(f,g \in B(X)\) and \(f(x) \le g(x)\) for all \(x\in X\) implies \(T(f)(x) \le T(g)(x)\) for all \(x\in X\),
(discounting) There exists \(\beta \in (0,1)\) such that
Then \(T\) is a contraction mapping with modulus \(\beta\).
Monotonicity of Bellman equation follows trivially due to maximization in \(T(V)(x)\)
Discounting: satisfied by elementary argument when \(\beta<1\)
Bellman operator is contraction mapping by Blackwell condition as long as the value function is bounded and the discount factor is less than one
In practical application with the upper bound on the state space, the value function is generally bounded
In many applications the norm \(\rho\) in the metric space can be adjusted to make the value function bounded
\(\Rightarrow\)
unique solution
VFI algorithm is globally convergent
does not depend on the numerical implementation of the Bellman operator
Inventory management in infinite horizon#
Example
Return to the above example, now with the following modifications:
time horizon is infinite
demand is stochastic with known distribution
After dropping the time subscripts the Bellman equation is
The sum in the RHS of the equation computes the expectation over realizations of discrete random demands \(d'\), each happening with probability \(pr(d')\).
We could solve the problem as is, but note that \(d\) does not enter the “next period part” of the Bellman equation (due to the assumption that demand is idiosyncratic). In this case we can make our life easier by converting the problem of searching for the fixed point of the Bellman operator to the problem of searching the fixed point of the expected Bellman operator.
Taking the expectation of the Bellman equation over the distribution of demand \(d\) on both sides, and denoting \(EV(x) = \sum_{d} V(x,d) pr(d)\), we have
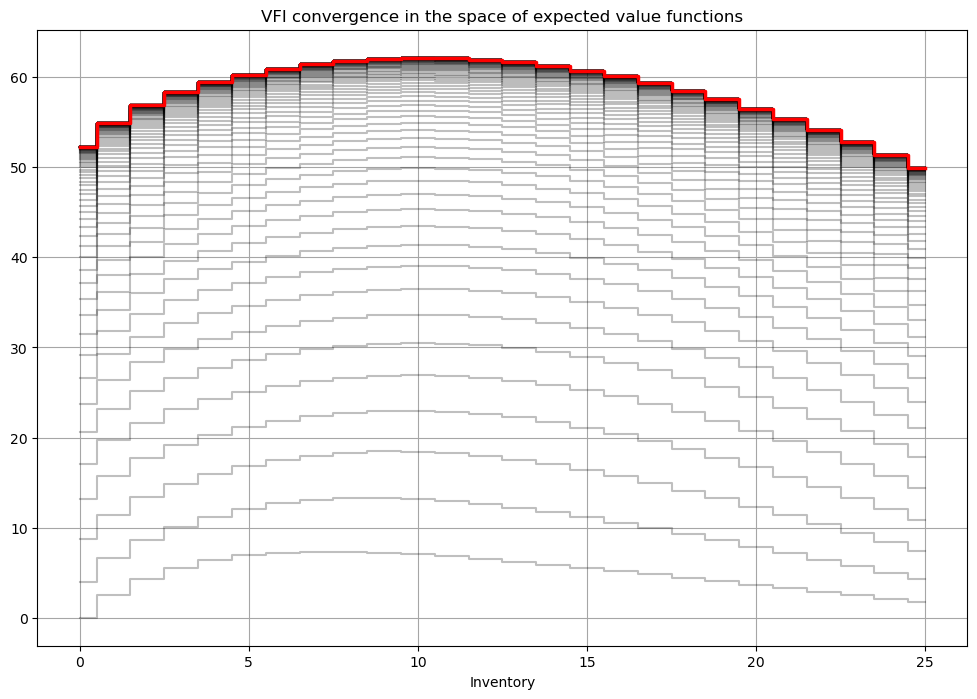
In the expected value function form the Bellman operator is also a contraction, but the fixed point now has to be solved only in the space of \(x\) and not \(x,d\). This is much easier for computational solver in the code below.
Show code cell source
def bellman_ev(m,ev0):
'''Bellman equation for inventory model
Inputs: model object
next period EXPECTED value function
'''
pr = m.demand_pr()
ev1 = np.zeros(shape=m.x.shape)
for j,d in enumerate(m.x): # over all values of demand
# create the grid of choices (same as x), column-vector
q = m.x[:,np.newaxis]
# compute current period profit (relying on numpy broadcasting to get the matrix with choices in rows)
p = m.profit(m.x,d,q)
# indexes for next period value with extrapolation using last value
i = np.minimum(m.next_x(m.x,d,q),m.upper)
# compute the Bellman maximand
vm = p + m.β*ev0[i]
# find max and argmax
v1 = np.amax(vm,axis=0) # maximum in every column
ev1 = ev1 + pr[j]*v1
q1 = None
return ev1, q1
def solve_vfi(self,tol=1e-6,maxiter=500,callback=None):
'''Solves the Rust model using value function iterations
'''
ev0 = np.zeros(self.n) # initial point for VFI
for i in range(maxiter): # main loop
ev1, q1 = bellman_ev(self,ev0) # update approximation
err = np.amax(np.abs(ev0-ev1))
if callback != None: callback(iter=i,err=err,ev1=ev1,ev0=ev0,q1=q1,model=self)
if err<tol:
break # break out if converged
ev0 = ev1 # get ready to the next iteration
else:
raise RuntimeError('Failed to converge in %d iterations'%maxiter)
return ev1, q1
def solve_show(self,maxiter=1000,tol=1e-6,**kvargs):
'''Illustrate solution'''
fig1, (ax) = plt.subplots(1,1,figsize=(12,8))
ax.grid(which='both', color='0.65', linestyle='-')
ax.set_xlabel('Inventory')
ax.set_title('VFI convergence in the space of expected value functions')
def callback(**argvars):
mod, ev, q = argvars['model'],argvars['ev1'],argvars['q1']
ax.step(mod.x,ev,color='k',alpha=0.25,where='mid')
ev,pk = solve_vfi(self,maxiter=maxiter,tol=tol,callback=callback,**kvargs)
# add solutions
ax.step(self.x,ev,color='r',linewidth=2.5,where='mid')
plt.show()
def optimal_policy(m,ev):
'''Computes the optimal policy function for the stochastic
inventory dynamics model for given EV function'''
# idea: 3-dim array with q in axes 0, d in axis 1 and x in axis 2
q = m.x[:,np.newaxis,np.newaxis] # choices
d = m.x[np.newaxis,:,np.newaxis] # demand
x = m.x[np.newaxis,np.newaxis,:] # inventories
# compute current period profit (relying on numpy broadcasting to get the matrix with choices in rows)
p = m.profit(x,d,q) # 3-dim array
# indexes for next period value with extrapolation using last value
i = np.minimum(m.next_x(x,d,q),m.upper)
# compute the Bellman maximand
vm = p + m.β*ev[i]
# find argmax and argmax
return np.argmax(vm,axis=0) # maximum in every column
# Set up the parameters of the model
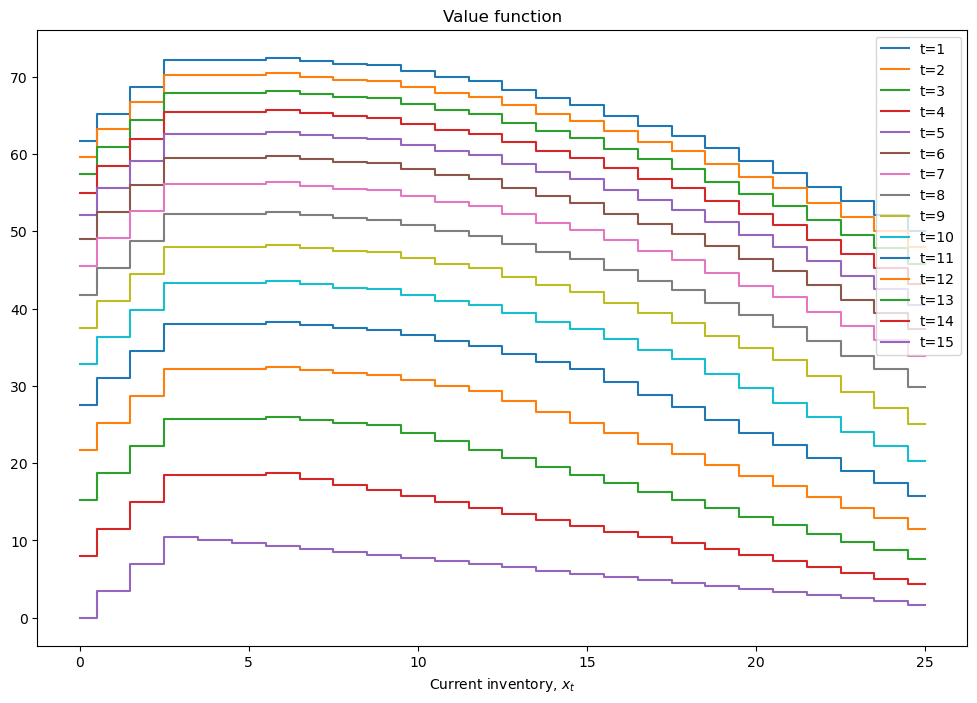
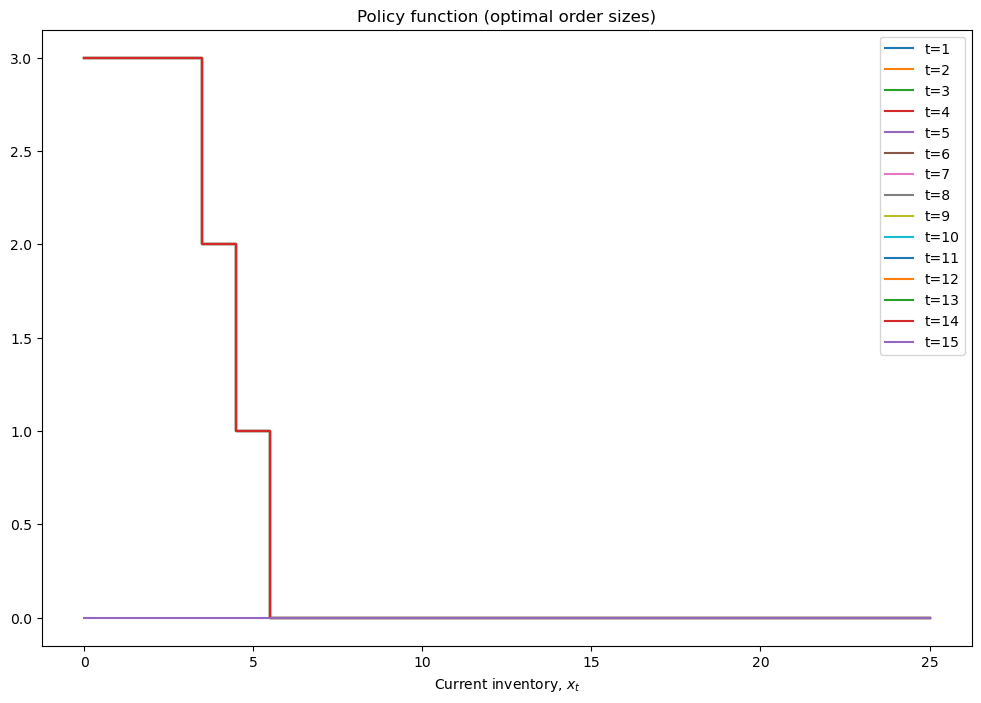
mod = inventory_model(label='production',max_inventory=25)
mod.dp=.25
mod.demand = int((1-mod.dp)/mod.dp) # mean for geometric distribution of demand
mod.c = .25
mod.p = 3.5
mod.r = 0.4
mod.β = 0.9
# solve the finite horizon version of the model with fixed demand
print(mod)
mod = solver_backwards_induction(mod,T=15)
plot_solution(mod)
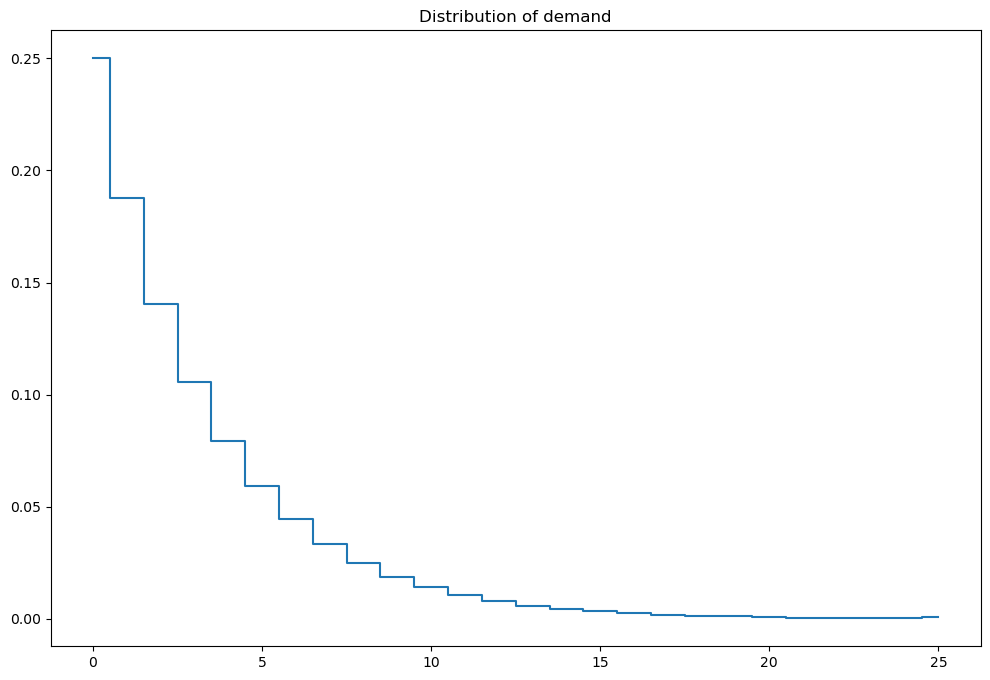
# visualize the stochastic demand
mod.demand_pr(plot=True)
# solve the infinite horizon version of the model
ev,q = solve_vfi(mod)
solve_show(mod)
q = optimal_policy(mod,ev)
print('Optimal orders of new inventory for d,x:\n(d in rows, x in columns)')
print(q)
Inventory model labeled "production"
Paramters (c,p,r,β) = (0.25,3.5,0.4,0.9)
Demand=3
Upper bound on inventory 25
Optimal orders of new inventory for d,x:
(d in rows, x in columns)
[[7 6 5 4 3 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[7 7 6 5 4 3 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[7 7 7 6 5 4 3 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[7 7 7 7 6 5 4 3 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[7 7 7 7 7 6 5 4 3 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[7 7 7 7 7 7 6 5 4 3 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[7 7 7 7 7 7 7 6 5 4 3 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[7 7 7 7 7 7 7 7 6 5 4 3 2 0 0 0 0 0 0 0 0 0 0 0 0 0]
[7 7 7 7 7 7 7 7 7 6 5 4 3 2 0 0 0 0 0 0 0 0 0 0 0 0]
[7 7 7 7 7 7 7 7 7 7 6 5 4 3 2 0 0 0 0 0 0 0 0 0 0 0]
[7 7 7 7 7 7 7 7 7 7 7 6 5 4 3 2 0 0 0 0 0 0 0 0 0 0]
[7 7 7 7 7 7 7 7 7 7 7 7 6 5 4 3 2 0 0 0 0 0 0 0 0 0]
[7 7 7 7 7 7 7 7 7 7 7 7 7 6 5 4 3 2 0 0 0 0 0 0 0 0]
[7 7 7 7 7 7 7 7 7 7 7 7 7 7 6 5 4 3 2 0 0 0 0 0 0 0]
[7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 6 5 4 3 2 0 0 0 0 0 0]
[7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 6 5 4 3 2 0 0 0 0 0]
[7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 6 5 4 3 2 0 0 0 0]
[7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 6 5 4 3 2 0 0 0]
[7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 6 5 4 3 2 0 0]
[7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 6 5 4 3 2 0]
[7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 6 5 4 3 2]
[7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 6 5 4 3]
[7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 6 5 4]
[7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 6 5]
[7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 6]
[7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7]]
Note
Note the symmetry in the optimal policy! This implies that knowing both \(x\) and \(d\) is not necessary for the optional new order, it’s enough to condition on the inventory remaining after sales, i.e. \(x-\min(x,d) = \max(0,x-d)\)
Other classes of dynamic optimization problems#
Classification of dynamic problems by various criteria:
Nature of time
discrete time: here
continuous time: studied in the calculus of variation, optimal control theory and other branches of math
Uncertainty in the beliefs of the decision makers
deterministic problems: all transition rules are given by laws of motion, i.e. mappings from states and choices to next period states
stochastic problems: some transitions rules are given by conditional densities or transition probabilities from current to next period states
Nature of choice space
discrete: well suited for numerical full enumeration methods (grid search)
continuous: optimization theory of this course applied in full
mixed discrete-continuous: math is more complicated and interesting
Nature of state space
discrete: well suited for numerical methods
continuous: most often convert to discrete by discretization (grids)
mixed discrete-continuous
Multiple decision making processes
single agent models: here
equilibrium models: each decision makers takes environment variables as given, yet the equilibrium environment is formed by the aggregate behavior
multiple agents models: strategic interaction between decision makers, very hard because the joint Bellman operator is no more a contraction
Corresponding to many types of dynamic optimization problems there are many-many variations of the solution approaches
For finite horizon dynamic problems:
Standard backwards induction: solving Bellman equation sequentially
Backwards induction using F.O.C. of Bellman maximization problem (for problems with continuous choice)
Finite horizon version of endogenous gridpoint method (for a particular class of problems)
For infinite horizon dynamic problems:
Value function iterations (successive approximations to solve for the fixed point of Bellman operator)
Time iterations (successive approximations to solve for the fixed point of Coleman-Reffett operator in policy function space)
Policy iteration method (Howard’s policy improvement algorithm, iterative solution for the fixed point of Bellman operator)
Newton-Kantorovich method (Newton solver for the fixed point of Bellman operator)
Endogenous gridpoint method (for a particular class of problems)
Extra material#
Computer science view on DP https://www.techiedelight.com/introduction-dynamic-programming
Popular optimal stopping https://www.americanscientist.org/article/knowing-when-to-stop
For more details the inventory problem see my screencast on writing this code
For more dynamic programming and numerical methods see my Foundations of Computational Economics online course