Constrained optimization#
ECON2125/6012 Lecture 8 Fedor Iskhakov
Announcements & Reminders
Submit Test 3 before October 4, 23:59
The test will include the material from the last two lectures (unconstrained and constrained optimization) with some additional material on fundamentals of optimization from the lecture before (properties of optima and convexity)
Next week you will have a guest lecture by Dr. Esben Scriver Andersen who is a postdoc at RSE working on structural estimation of dynamic discrete choice and matching models
Topic: numerical methods for practical optimization problems

Plan for this lecture
Constrained vs unconstrained optimization
Equality constrains and Lagrange method
Inequality constrains and Kuhn-Tucker method
Constrained optimization under convexity
Supplementary reading:
Simon & Blume: 16.2, whole of chapter 18, 19.3
Sundaram: chapters 5 and 6
Setting up a constrained optimization problem#
Let’s start with recalling the definition of a general optimization problem
Definition
The general form of the optimization problem is
where:
\(f(x,\theta) \colon \mathbb{R}^N \times \mathbb{R}^K \to \mathbb{R}\) is an objective function
\(x \in \mathbb{R}^N\) are decision/choice variables
\(\theta \in \mathbb{R}^K\) are parameters
\(g_i(x,\theta) = 0, \; i\in\{1,\dots,I\}\) where \(g_i \colon \mathbb{R}^N \times \mathbb{R}^K \to \mathbb{R}\), are equality constraints
\(h_j(x,\theta) \le 0, \; j\in\{1,\dots,J\}\) where \(h_j \colon \mathbb{R}^N \times \mathbb{R}^K \to \mathbb{R}\), are inequality constraints
\(V(\theta) \colon \mathbb{R}^K \to \mathbb{R}\) is a value function
Today we focus on the problem with constrants, i.e. \(I+J>0\)
The obvious classification that we follow
equality constrained problems, i.e. \(I>0\), \(J=0\)
inequality constrained problems, i.e. \(J>0\), which can include equalities as special case
Note
Note that every optimization problem can be seen as constrained if we define the objective function to have the domain that coincides with the admissible set.
is equivalent to
Equality constrains and Lagrange method#
Constrained Optimization#
A major focus of econ: the optimal allocation of scarce resources
optimal = optimization
scarce = constrained
Standard constrained problems:
Maximize utility given budget
Maximize portfolio return given risk constraints
Minimize cost given output requirement
Example
Maximization of utility subject to budget constraint
\(p_i\) is the price of good \(i\), assumed \(> 0\)
\(m\) is the budget, assumed \(> 0\)
\(x_i \geq 0\) for \(i = 1,2\)
let \(u(x_1, x_2) = \alpha \log(x_1) + \beta \log(x_2)\), \(\alpha>0\), \(\beta>0\)
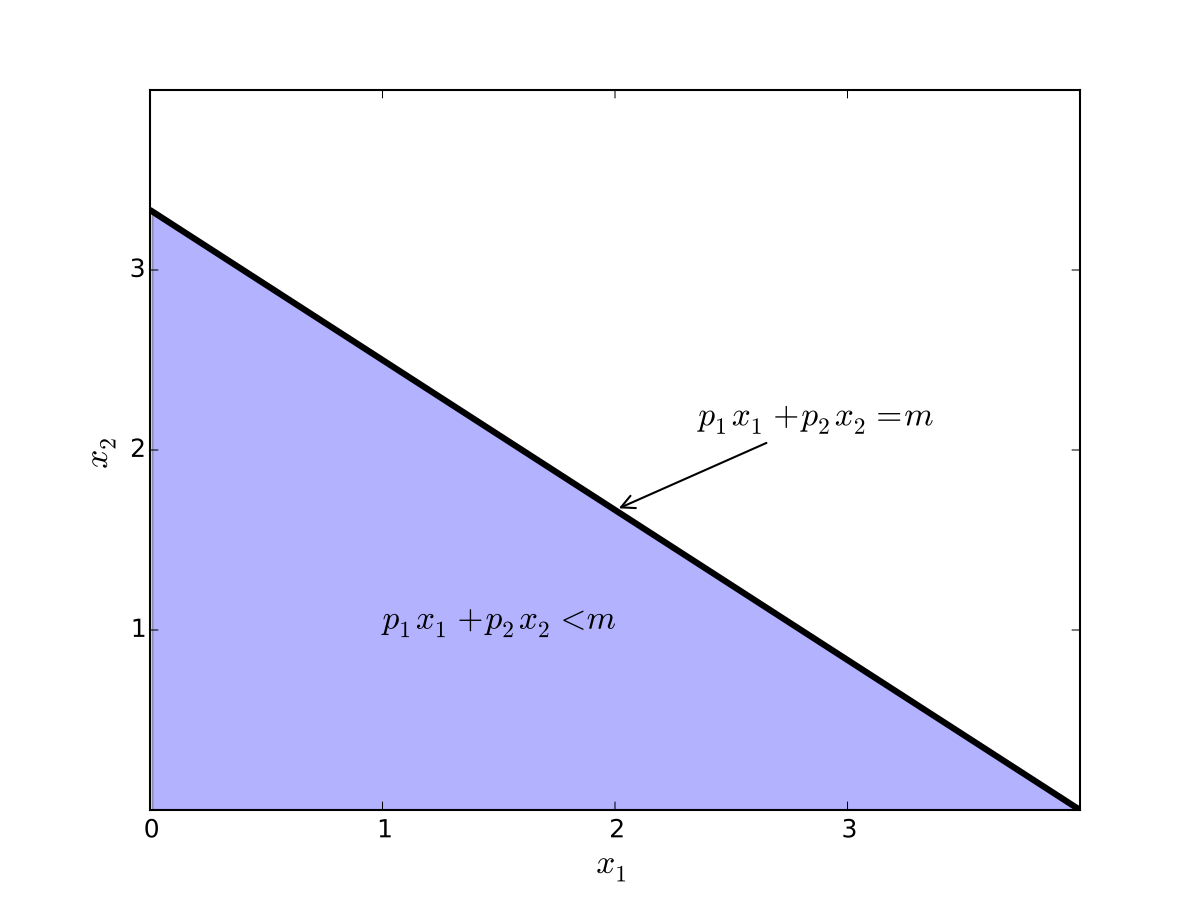
Fig. 86 Budget set when, \(p_1=1\), \(p_2 = 1.2\), \(m=4\)#
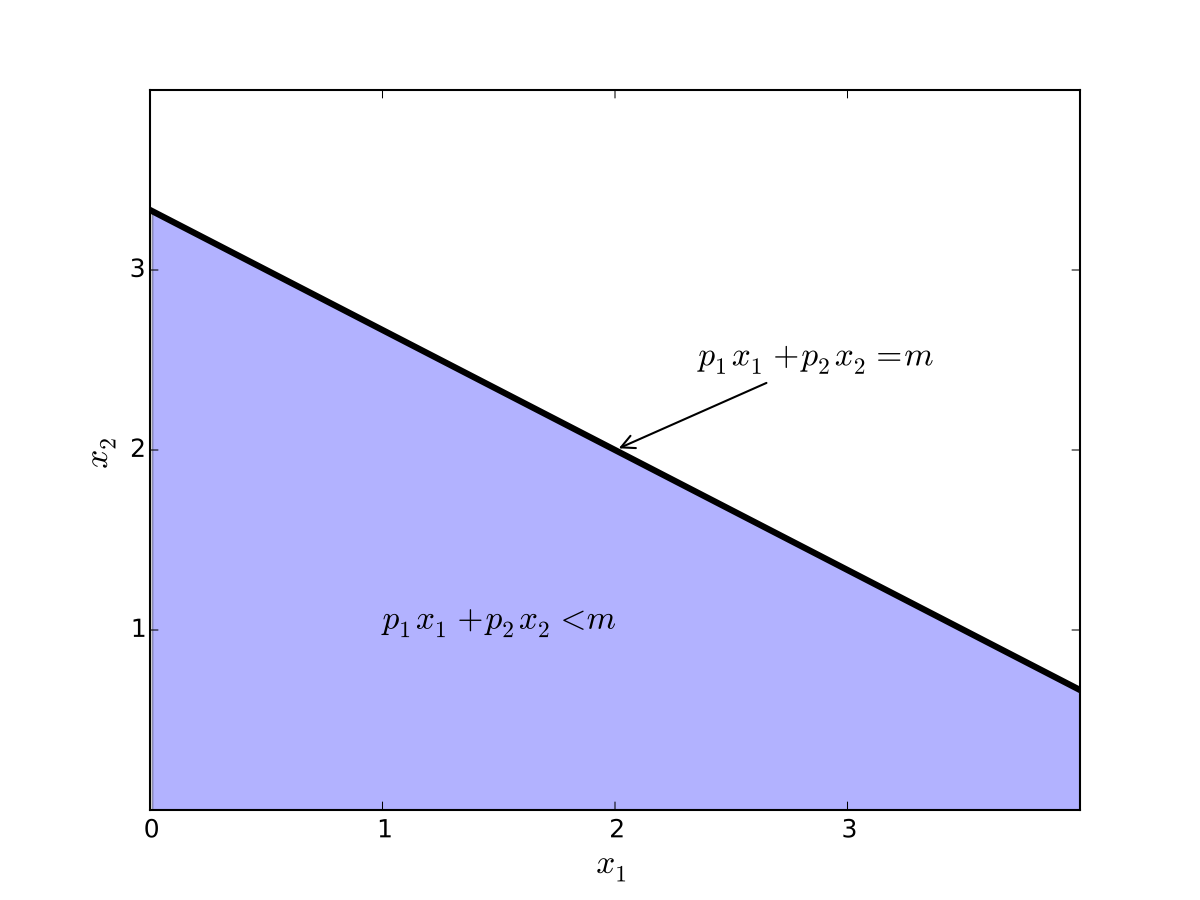
Fig. 87 Budget set when, \(p_1=0.8\), \(p_2 = 1.2\), \(m=4\)#
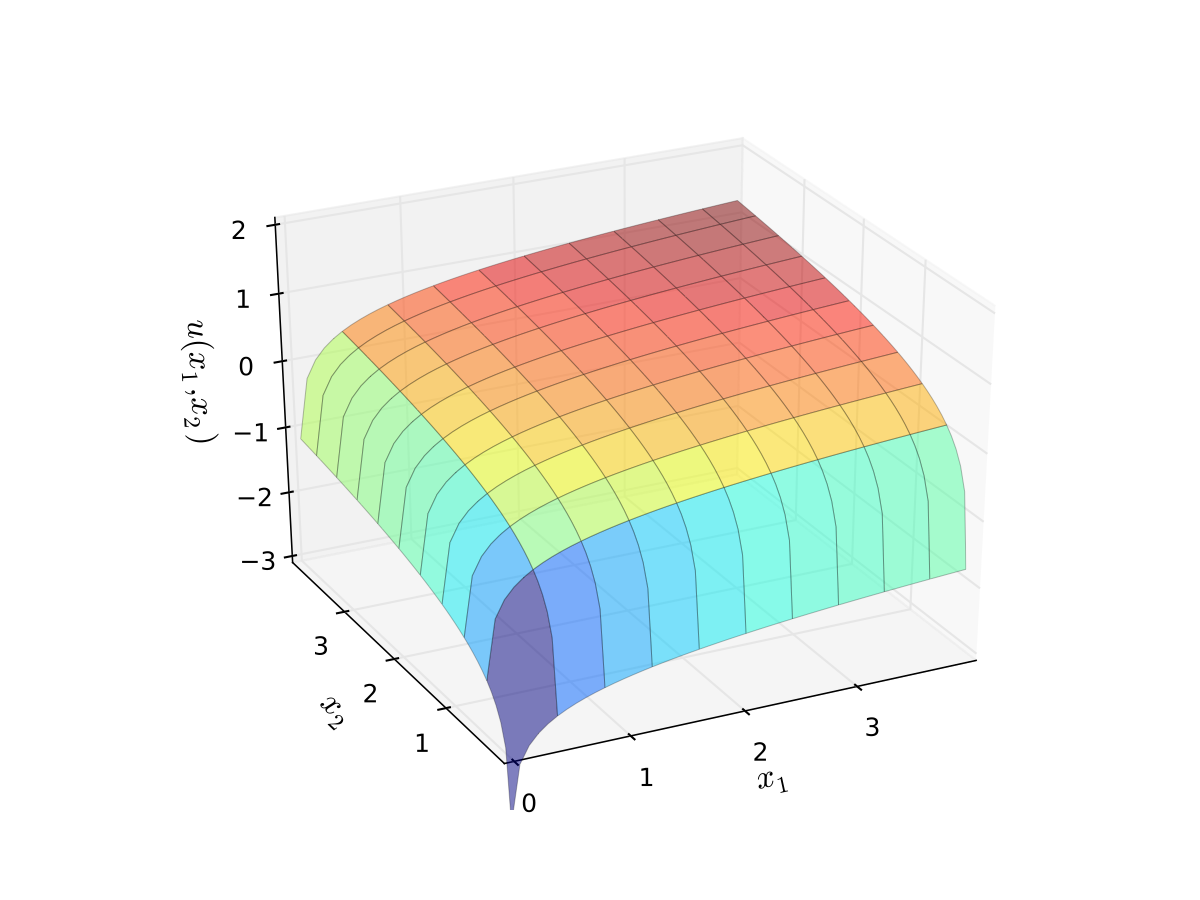
Fig. 88 Log utility with \(\alpha=0.4\), \(\beta=0.5\)#
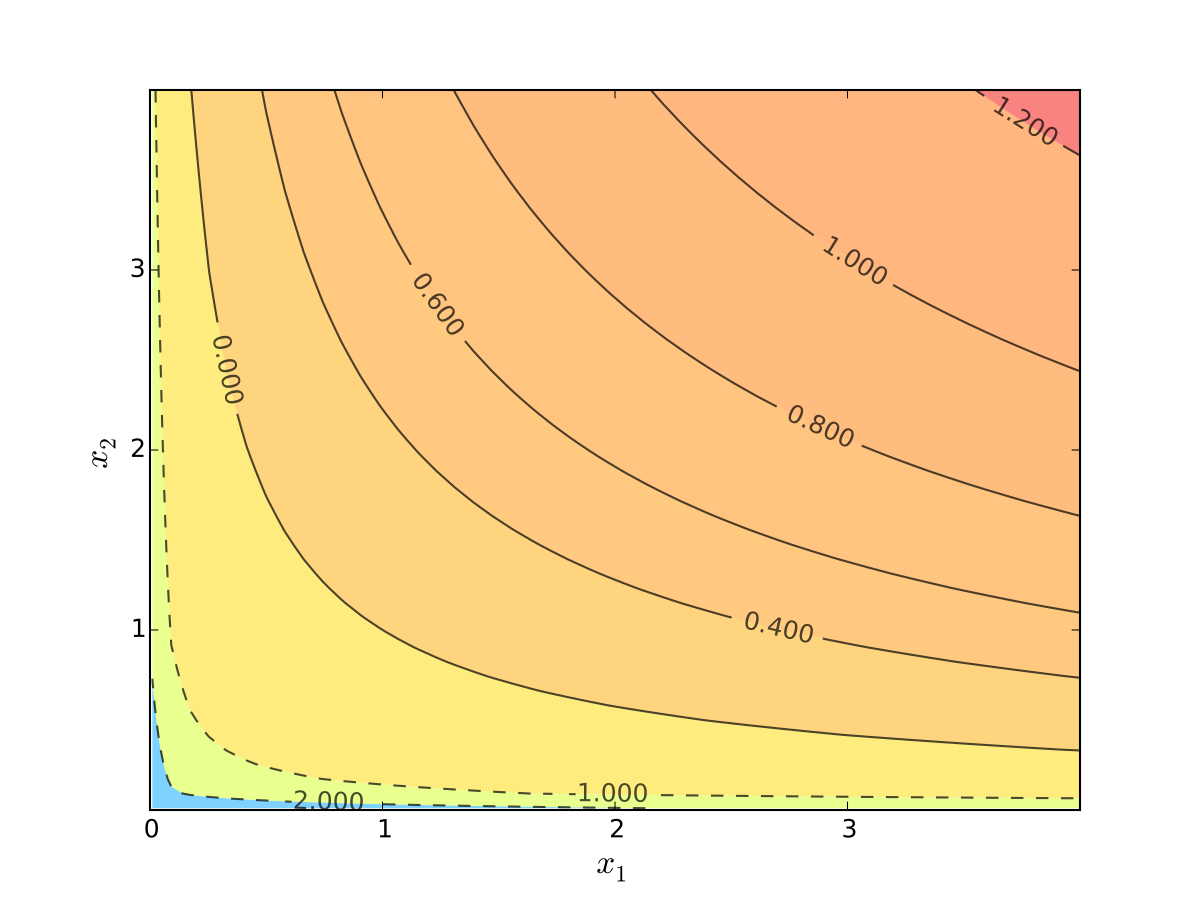
Fig. 89 Log utility with \(\alpha=0.4\), \(\beta=0.5\)#
We seek a bundle \((x_1^\star, x_2^\star)\) that maximizes \(u\) over the budget set
That is,
for all \((x_1, x_2)\) satisfying \(x_i \geq 0\) for each \(i\) and
Visually, here is the budget set and objective function:
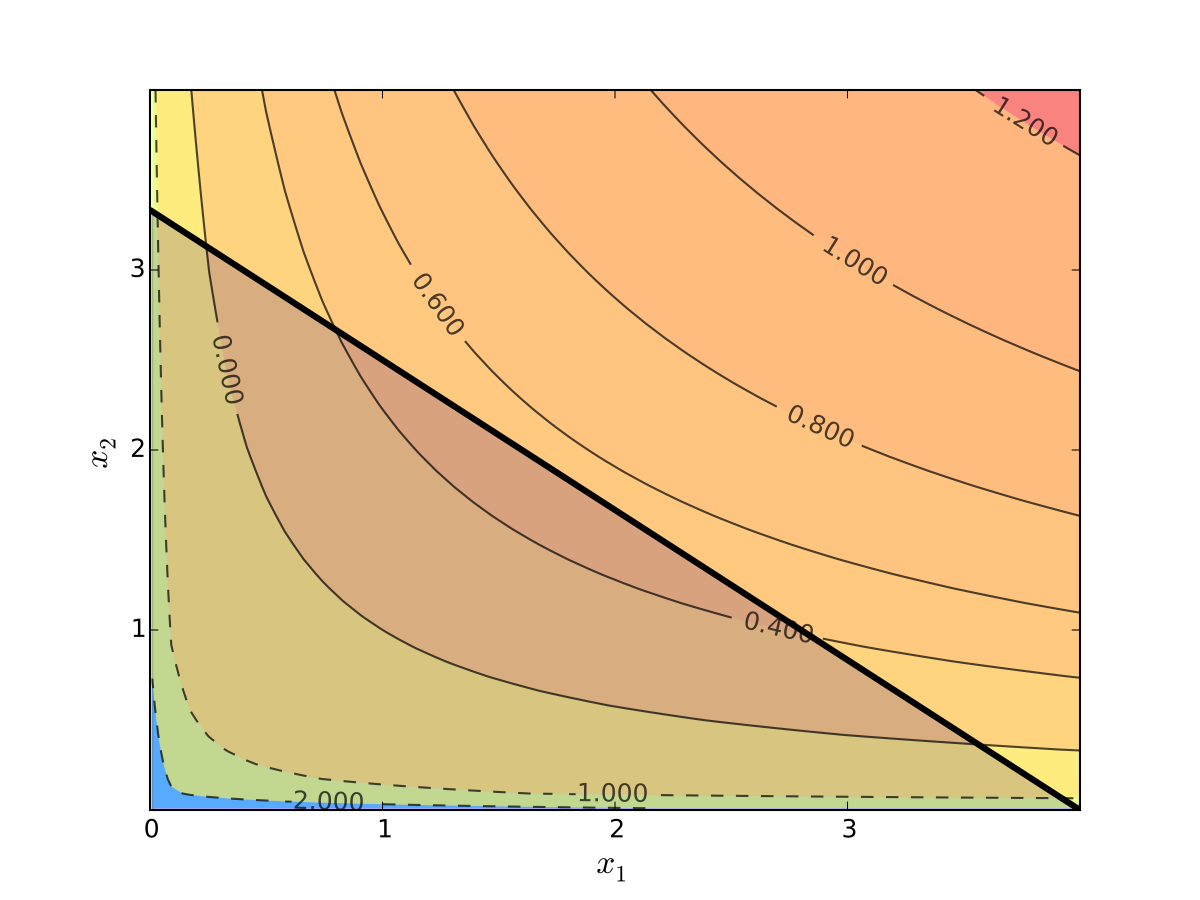
Fig. 90 Utility max for \(p_1=1\), \(p_2 = 1.2\), \(m=4\), \(\alpha=0.4\), \(\beta=0.5\)#
First observation: \(u(0, x_2) = u(x_1, 0) = u(0, 0) = -\infty\)
Hence we need consider only strictly positive bundles
Second observation: \(u(x_1, x_2)\) is strictly increasing in both \(x_i\)
Never choose a point \((x_1, x_2)\) with \(p_1 x_1 + p_2 x_2 < m\)
Otherwise can increase \(u(x_1, x_2)\) by small change
Hence we can replace \(\leq\) with \(=\) in the constraint
Implication: Just search along the budget line
Substitution Method#
Substitute constraint into objective function
This changes
into
Since all candidates satisfy \(x_1 > 0\) and \(x_2 > 0\), the domain is
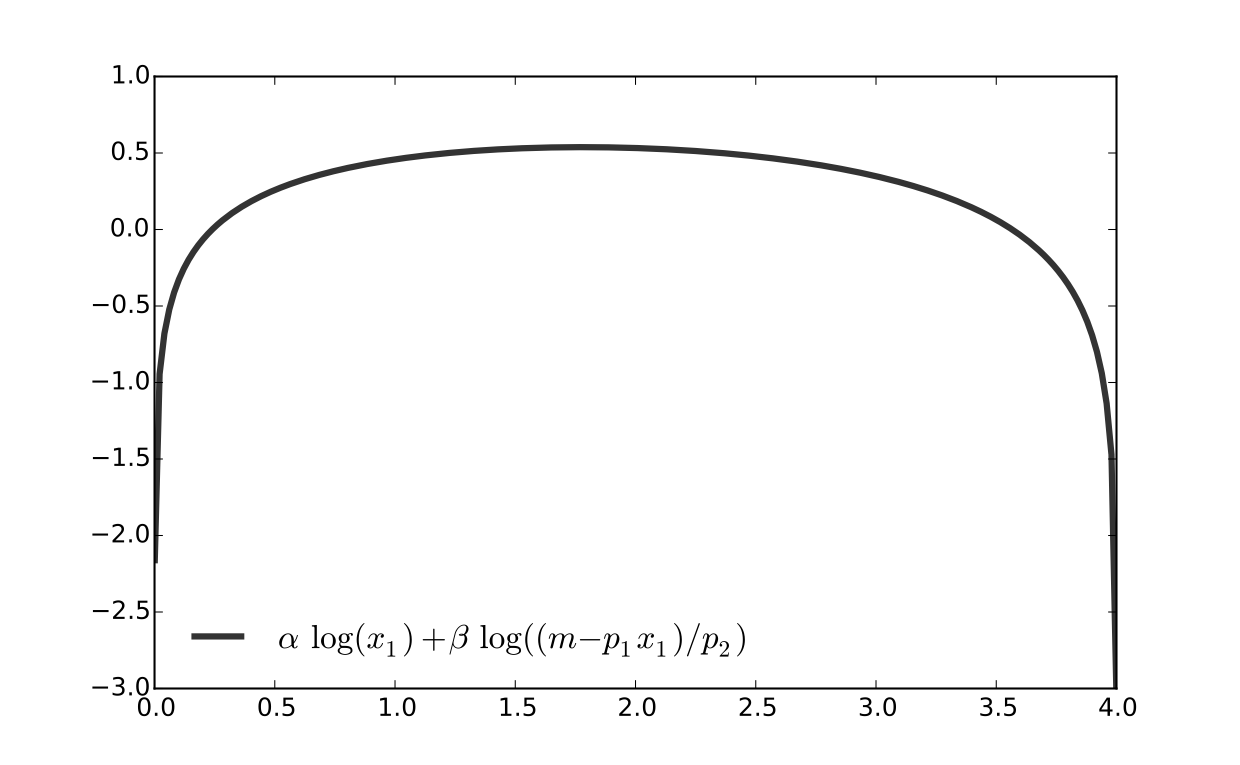
Fig. 91 Utility max for \(p_1=1\), \(p_2 = 1.2\), \(m=4\), \(\alpha=0.4\), \(\beta=0.5\)#
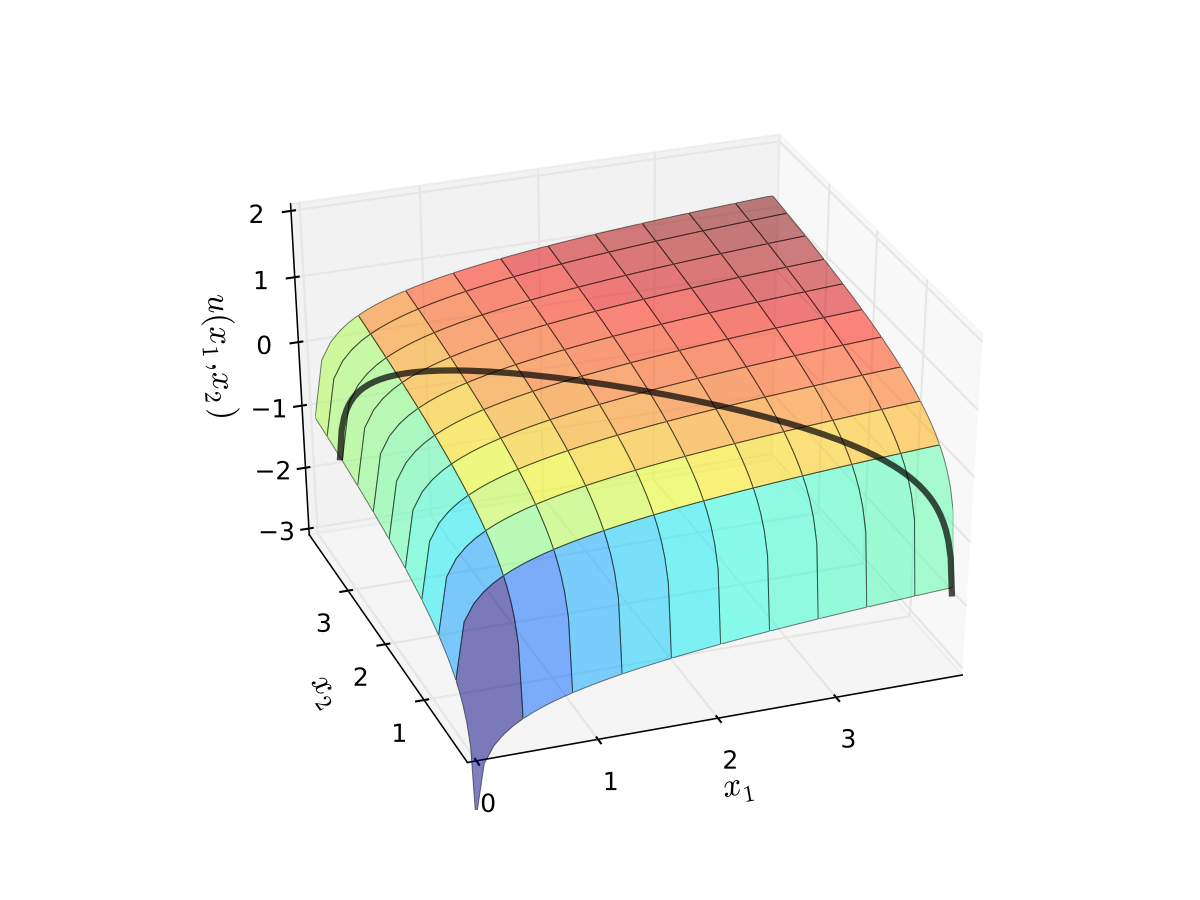
Fig. 92 Utility max for \(p_1=1\), \(p_2 = 1.2\), \(m=4\), \(\alpha=0.4\), \(\beta=0.5\)#
First order condition for
gives
Exercise: Verify
Exercise: Check second order condition (strict concavity)
Substituting into \(p_1 x_1^\star + p_2 x_2^\star = m\) gives
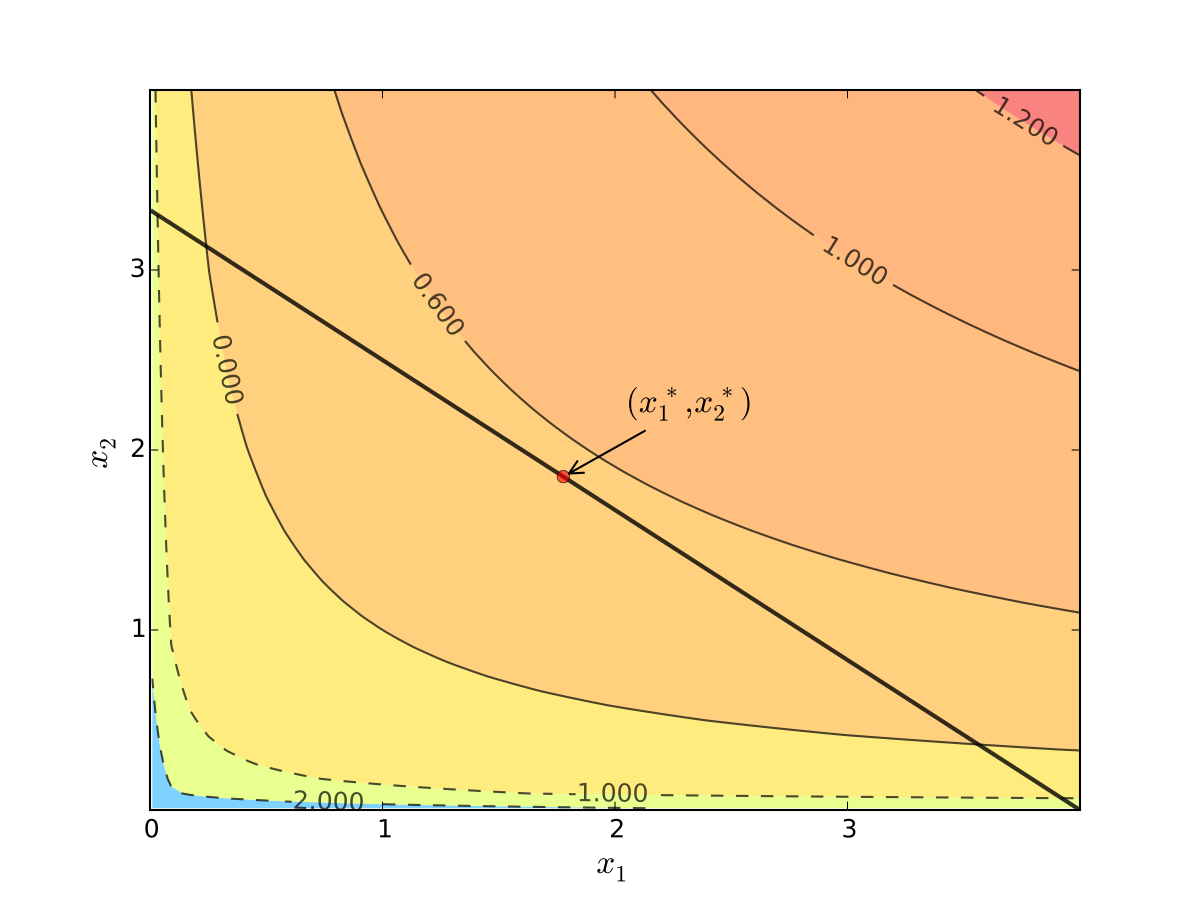
Fig. 93 Maximizer for \(p_1=1\), \(p_2 = 1.2\), \(m=4\), \(\alpha=0.4\), \(\beta=0.5\)#
Substitution method: recipe#
How to solve
Steps:
Write constraint as \(x_2 = h(x_1)\) for some function \(h\)
Solve univariate problem \(\max_{x_1} f(x_1, h(x_1))\) to get \(x_1^\star\)
Plug \(x_1^\star\) into \(x_2 = h(x_1)\) to get \(x_2^\star\)
Limitations: substitution doesn’t always work
Example
Suppose that \(g(x_1, x_2) = x_1^2 + x_2^2 - 1\)
Step 1 from the cookbook says
use \(g(x_1, x_2) = 0\) to write \(x_2\) as a function of \(x_1\)
But \(x_2\) has two possible values for each \(x_1 \in (-1, 1)\)
In other words, \(x_2\) is not a well defined function of \(x_1\)
As we meet more complicated constraints such problems intensify
Constraint defines complex curve in \((x_1, x_2)\) space
Inequality constraints, etc.
We need more general, systematic approach
Tangency#
Consider again the problem
Turns out that the maximizer has the following property:
budget line is tangent to an indifference curve at maximizer
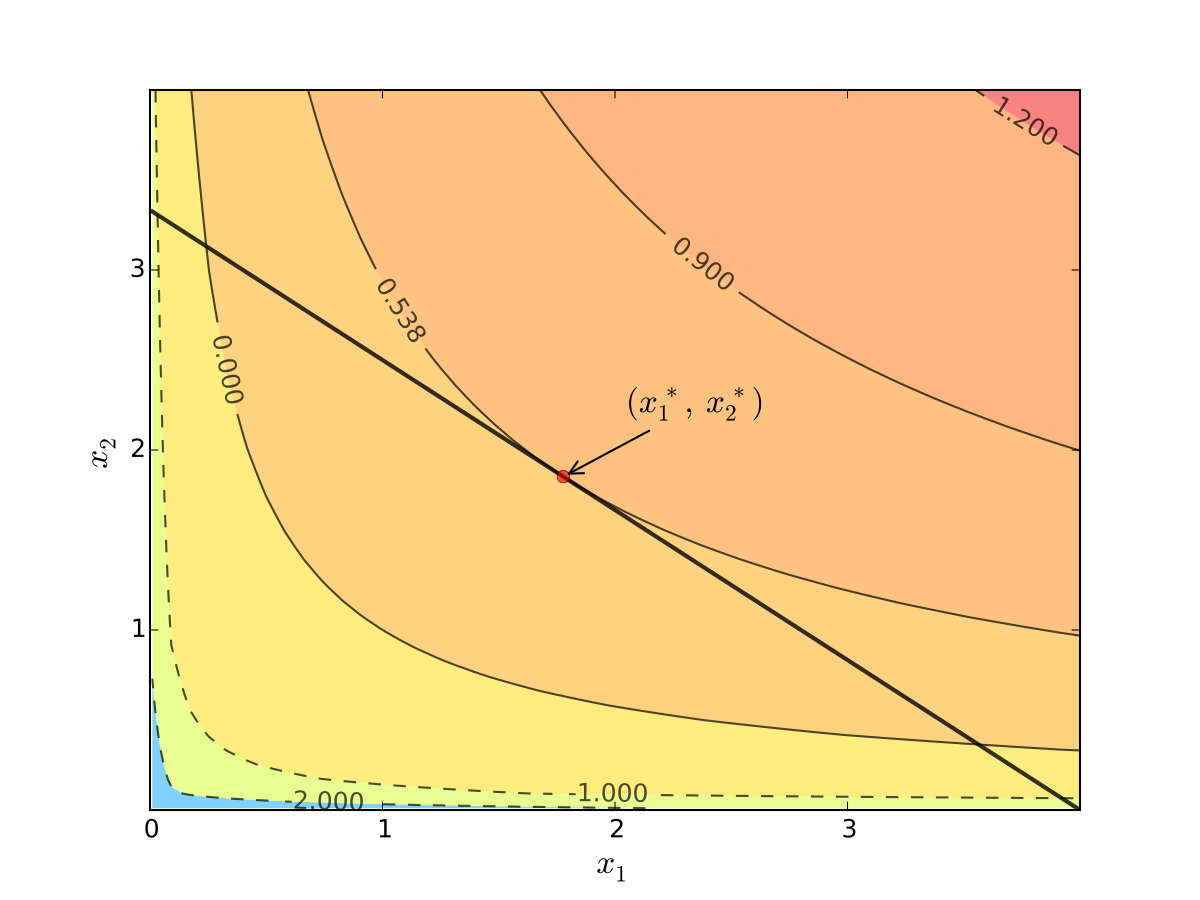
Fig. 94 Maximizer for \(p_1=1\), \(p_2 = 1.2\), \(m=4\), \(\alpha=0.4\), \(\beta=0.5\)#
In fact this is an instance of a general pattern
Notation: Let’s call \((x_1, x_2)\) interior to the budget line if \(x_i > 0\) for \(i=1,2\) (not a “corner” solution, see below)
In general, any interior maximizer \((x_1^\star, x_2^\star)\) of differentiable utility function \(u\) has the property: budget line is tangent to a contour line at \((x_1^\star, x_2^\star)\)
Otherwise we can do better:
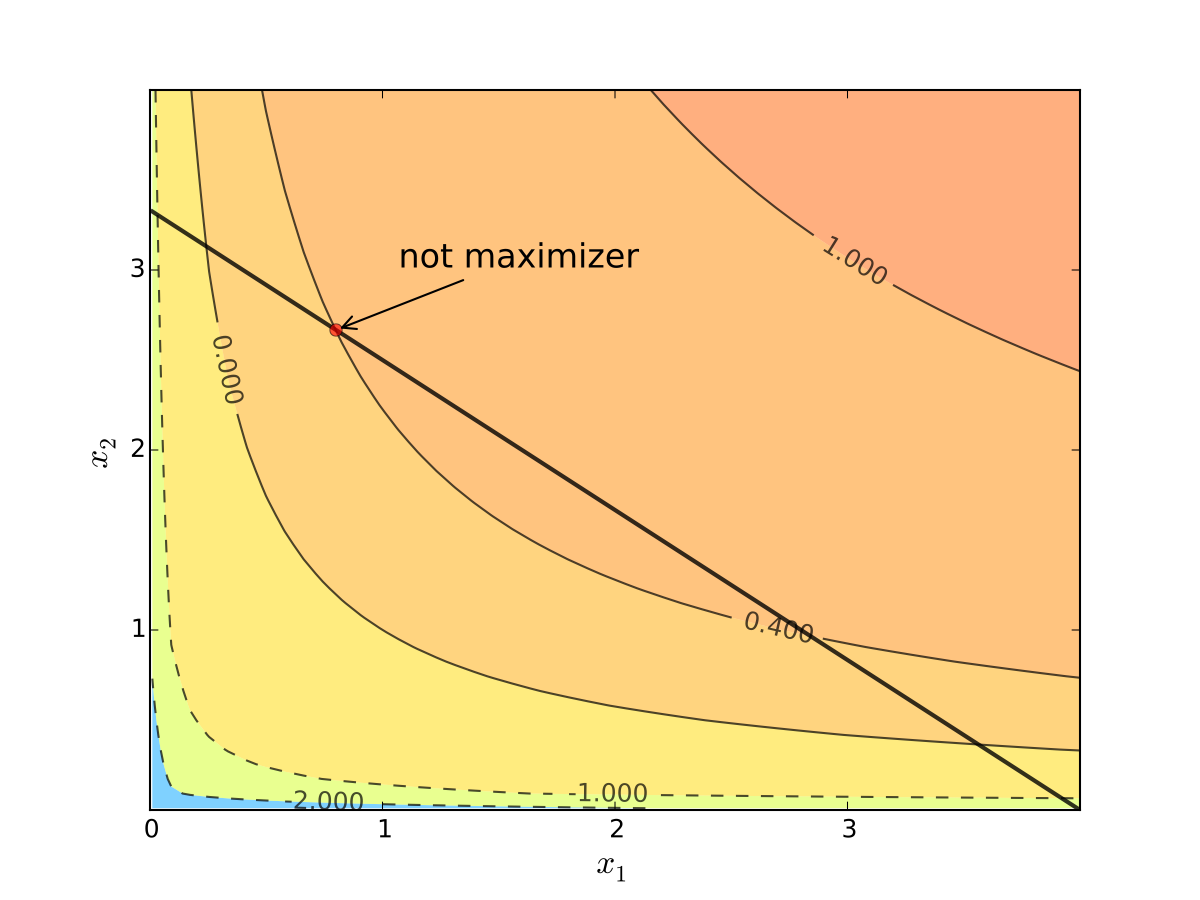
Fig. 95 When tangency fails we can do better#
Necessity of tangency often rules out a lot of points. We exploit this fact to
Build intuition
Develop more general methods
Diversion: derivative of an implicit function
To continue with the tangency approach we need to know how to differentiate an implicit function \(x_2(x_1)\) which is given by a contour line of the utility function \(f(x_1, x_2)=c\)
Let’s approach this task in the following way
utility function is given by \(f \colon \mathbb{R}^2 \to \mathbb{R}\)
the contour line is given by \(f(x_1,x_2) = c\) which defines an implicit function \(x_1(x_2)\)
let map \(g \colon \mathbb{R} \to \mathbb{R}^2\) given by \(g(x_2) = \big[x_1(x_2),x_2\big]\)
The total derivative of \(f \circ g\) can be derived using the chain rule
Differentiating the equation \(f(x_1,x_2) = c\) on both sides with respect to \(x_2\) gives \(D(f \circ g)({\bf x}) = 0\), thus leading to the final expression for the derivative of the implicit function
Using Tangency: Relative Slope Conditions#
Consider an equality constrained optimization problem where objective and constraint functions are differentiable:
How to develop necessary conditions for optima via tangency?
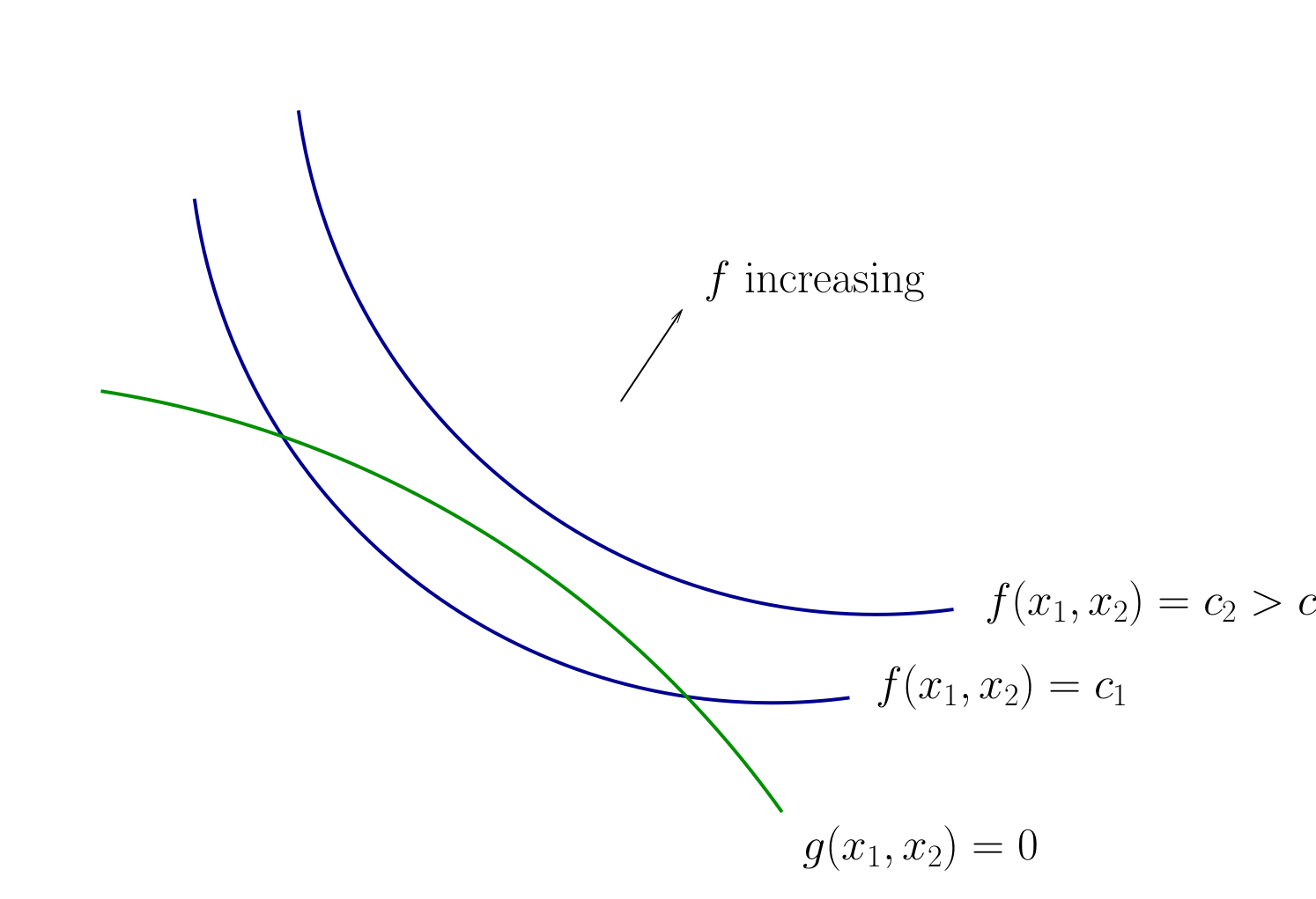
Fig. 96 Contours for \(f\) and \(g\)#
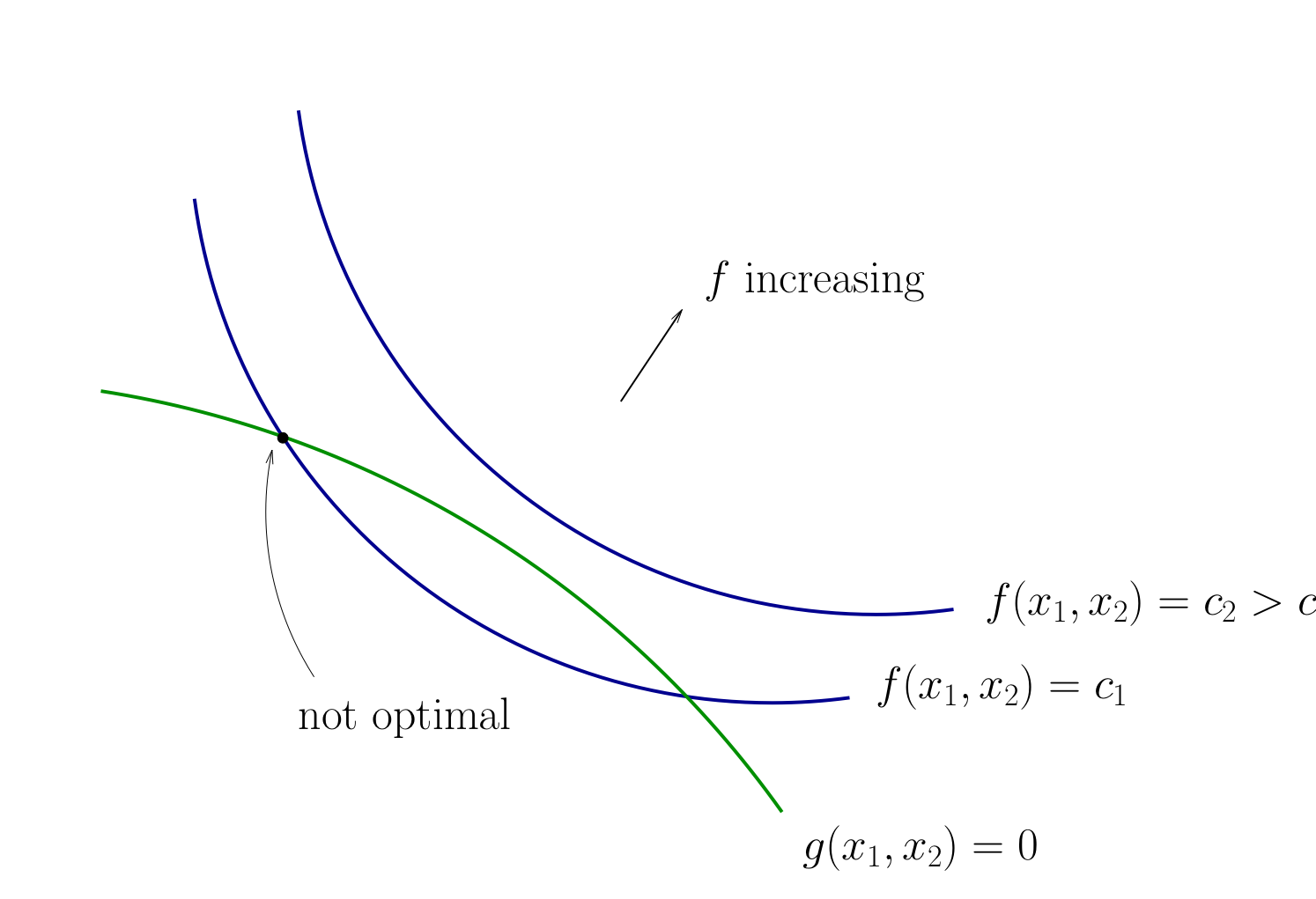
Fig. 97 Contours for \(f\) and \(g\)#
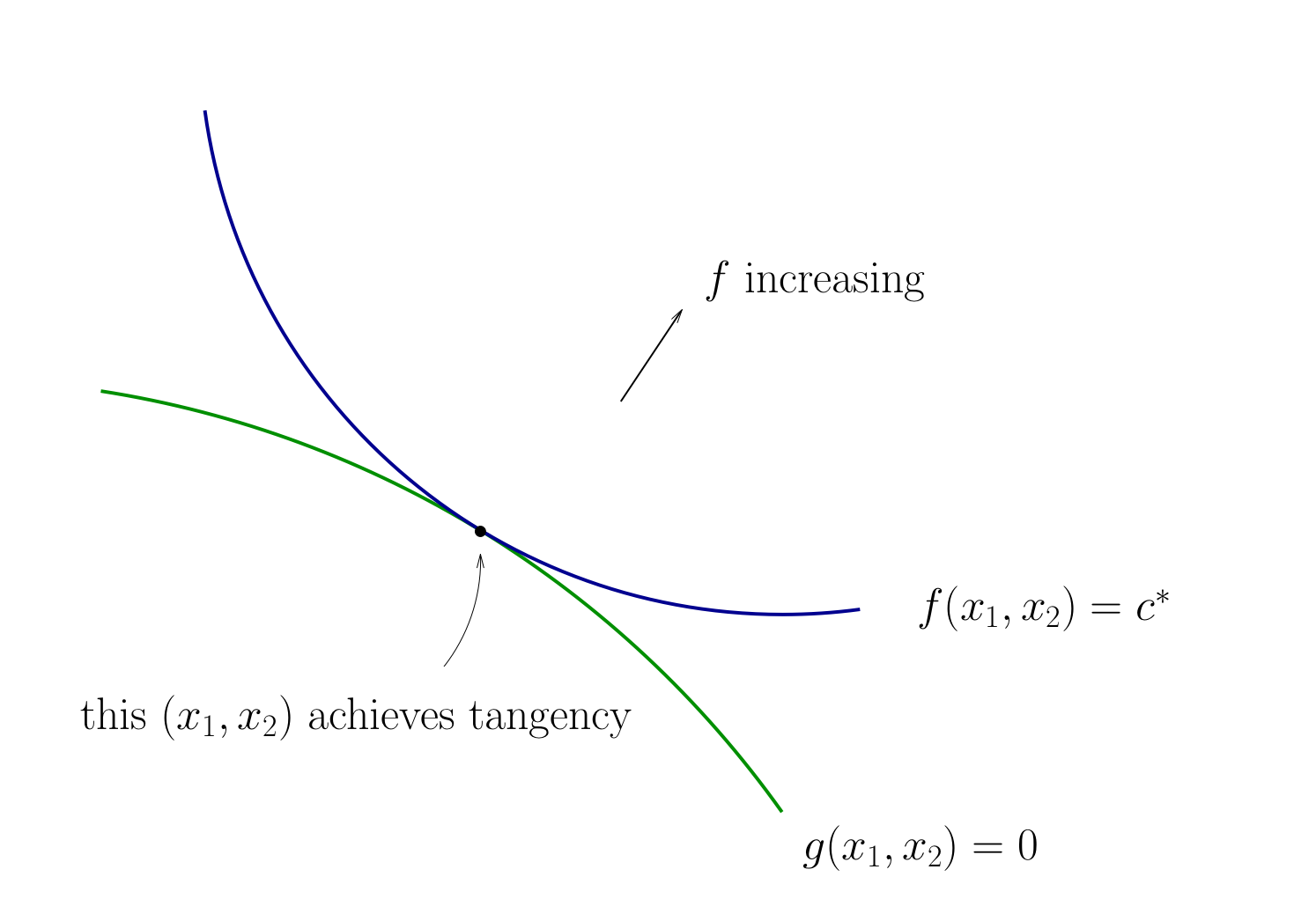
Fig. 98 Tangency necessary for optimality#
How do we locate an optimal \((x_1, x_2)\) pair?
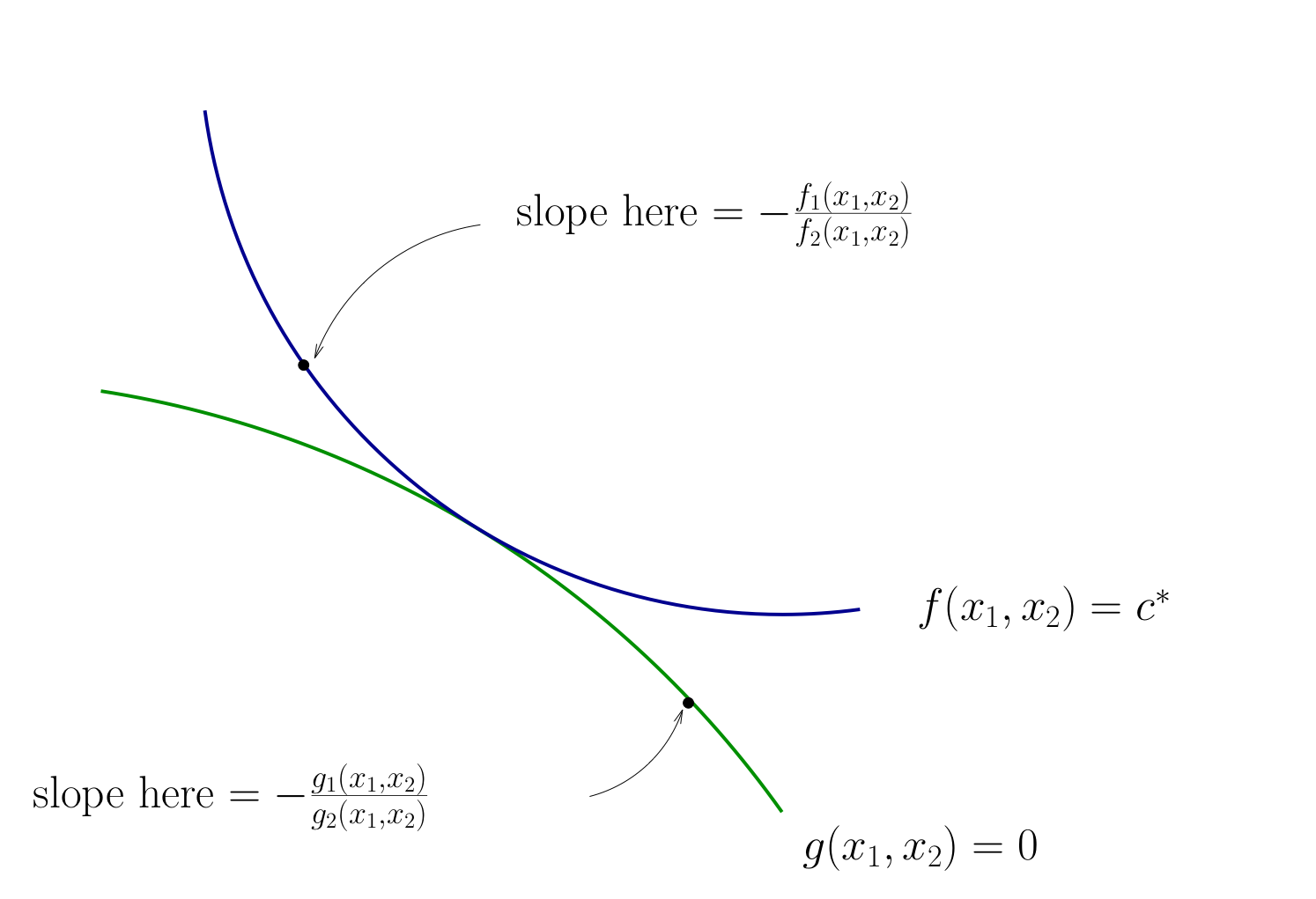
Fig. 99 Slope of contour lines#
Let’s choose \((x_1, x_2)\) to equalize the slopes
That is, choose \((x_1, x_2)\) to solve
Equivalent:
Also need to respect \(g(x_1, x_2) = 0\)
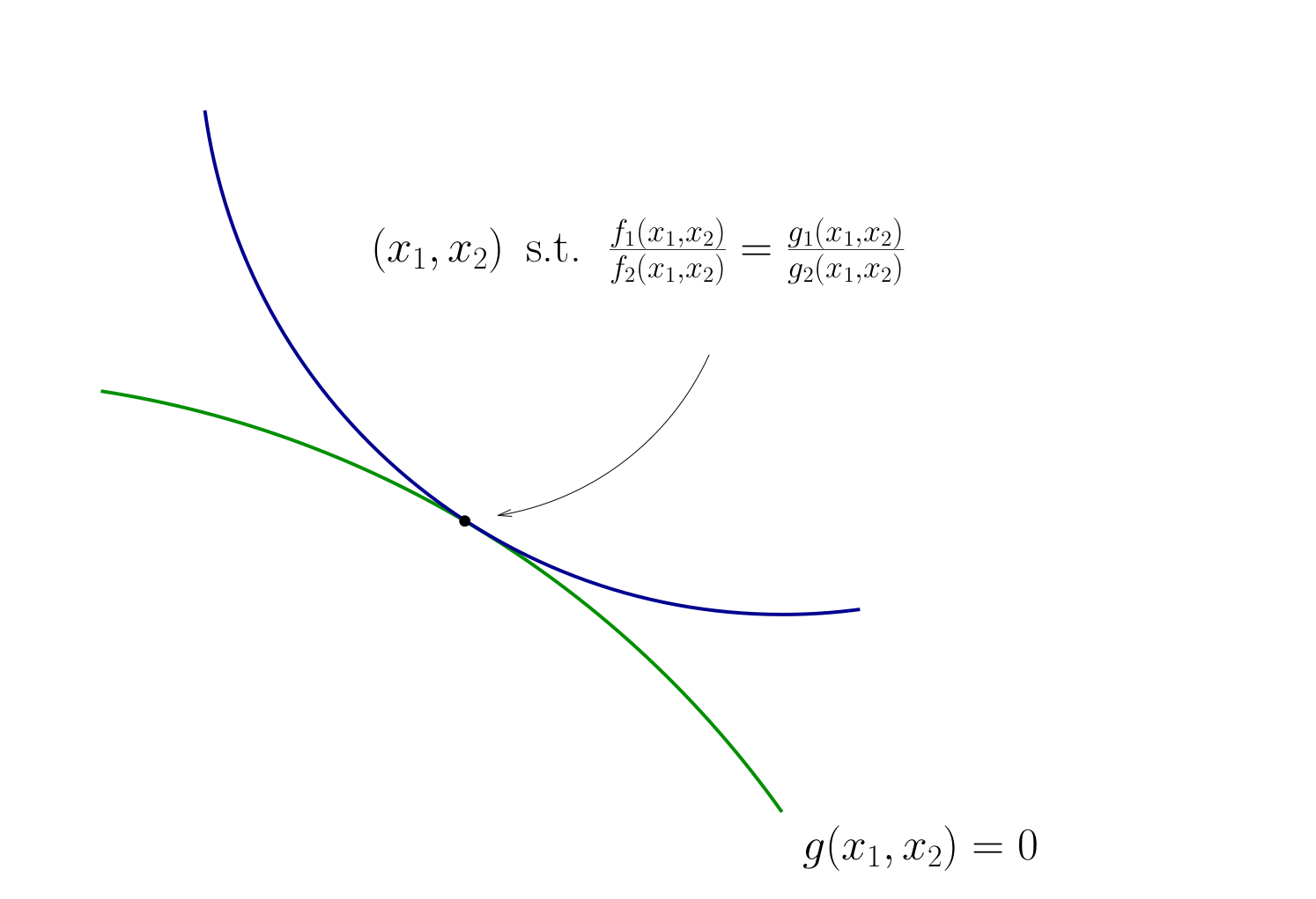
Fig. 100 Condition for tangency#
Tangency condition algorithm#
In summary, when \(f\) and \(g\) are both differentiable functions, to find candidates for optima in
(Impose slope tangency) Set
(Impose constraint) Set \(g(x_1, x_2) = 0\)
Solve simultaneously for \((x_1, x_2)\) pairs satisfying these conditions
Example
Consider again
Then
Solving simultaneously with \(p_1 x_1 + p_2 x_2 = m\) gives
Same as before…
Slope Conditions for Minimization#
Good news: The conditions are exactly the same
In particular:
Lack of tangency means not optimizer
Constraint must be satisfied
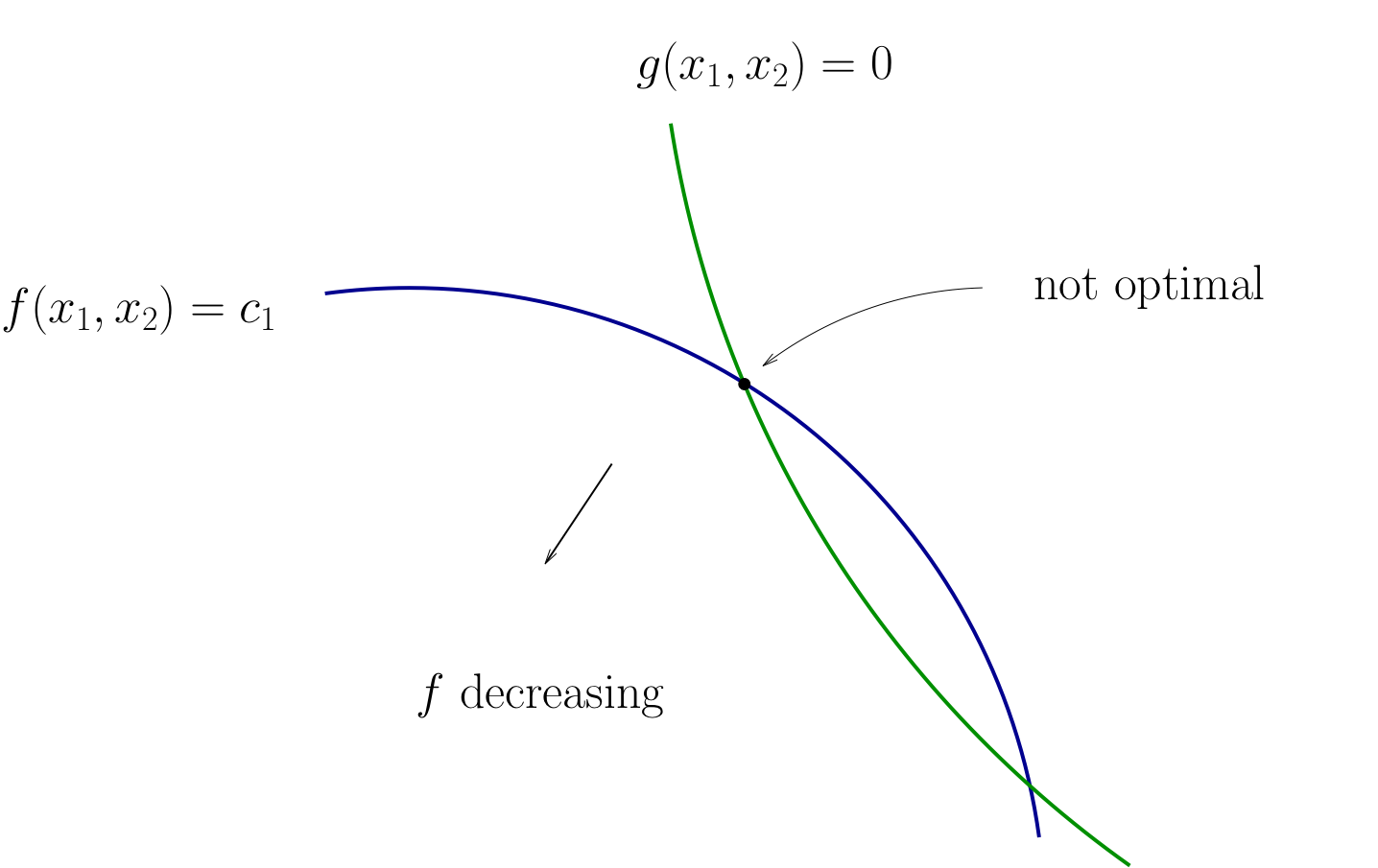
Fig. 101 Lack of tangency#
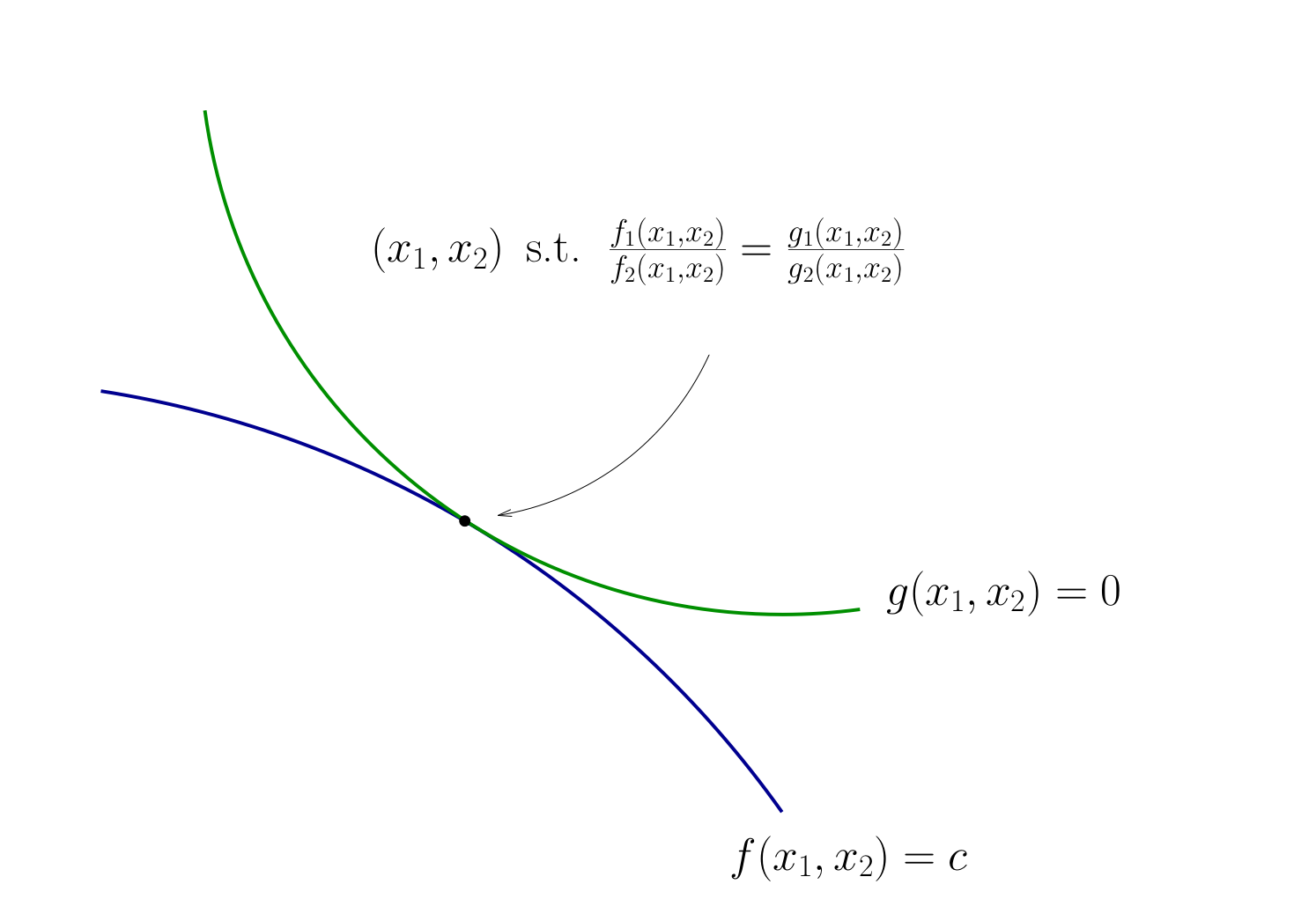
Fig. 102 Condition for tangency#
The method of Lagrange multipliers#
Lagrange theorem
Let \(f \colon \mathbb{R}^N \to \mathbb{R}\) and \(g \colon \mathbb{R}^N \to \mathbb{R}^K\) be continuously differentiable functions.
Let \(D = U \cap \{ {\bf x} \colon g_i({\bf x}) = 0, i=1,\dots,K \}\) where \(U \subset \mathbb{R}^N\) is an open set.
Suppose that \({\bf x}^\star \in D\) is a local extremum of \(f\) on \(D\) and that the gradients of the constraint functions \(g_i\) are linearly independent at \({\bf x}^\star\) (equivalently, the rank of the Jacobian matrix \(Dg({\bf x}^\star)\) is equal to \(K\))
Then there exists a vector \(\lambda^\star \in \mathbb{R}^K\) such that
Proof
See Sundaram 5.6, 5.7
Note
\(\lambda^\star\) is called the vector of Lagrange multipliers
The assumption that the gradients of the constraint functions \(g_i\) are linearly independent at \({\bf x}^\star\) is called the constraint qualification assumption
Lagrange theorem provides necessary first order conditions for both maximum and minimum problems
Definition
The function \(\mathcal{L} \colon \mathbb{R}^{N+K} \to \mathbb{R}\) defined as
is called a Lagrangian (function)
Different sources define the Lagrangian with minus or plus in front of the second term: mathematically the two definitions are equivalent, but the choice of the sign affects the interpretation of the Lagrange multipliers
I like to have a minus in the Lagrangian for consistency with the inequality constrained case where the sign is important
We come back to this in lecture 10
Fact
First order conditions for the Lagrangian coincide with the conditions in the Lagrange theorem, and together with the constraint qualification assumption they provide necessary first order conditions for the constrained optimization problem.
Example
Form the Lagrangian
FOC
From the first two equations we have \(x_1 = \frac{\alpha}{\lambda p_1}\) and \(x_2 = \frac{\beta}{\lambda p_2}\), and then from the third one \(\frac{\alpha}{\lambda} + \frac{\beta}{\lambda} = m\). This gives \(\lambda = \frac{\alpha + \beta}{m}\), leading to the same result
Lagrangian as tangency condition#
The “standard machine” for optimization with equality constraints
Set
and solve the system of
We have
Hence \(\frac{\partial \mathcal{L}}{\partial x_1} = \frac{\partial \mathcal{L}}{\partial x_2} = 0\) gives
Finally
Hence the method leads us to the same conditions as the tangency condition method!
Second order conditions#
similar to the unconstrained case, but applied to the Lagrangian
have to do with local optima only
similarly, provide sufficient conditions in the strict case, but only necessary conditions in the weak case
Using the rules of the differentiation from multivariate calculus we can express the gradient and the Hessian of the Lagrangian w.r.t. \({\bf x}\) as
Fact (necessary SOC)
Let \(f \colon \mathbb{R}^N \to \mathbb{R}\) and \(g \colon \mathbb{R}^N \to \mathbb{R}^K\) be twice continuously differentiable functions (\(C^2\)) and let \(D = U \cap \{ {\bf x} \colon g_i({\bf x}) = 0, i=1,\dots,K \}\) where \(U \subset \mathbb{R}^N\) is an open set.
Suppose \({\bf x}^\star \in D\) is the local constrained optimizer of \(f\) on \(D\) and that the constraint qualification assumption holds at \({\bf x}^\star\).
Then:
If \(f\) has a local maximum on \(D\) at \({\bf x}^\star\), then \(H_{\bf x} \mathcal{L}({\bf \lambda},{\bf x})\) defined above is negative semi-definite on a linear constraint set \(\{v: Dg({\bf x}^\star)\cdot v = {\bf 0}\}\), that is
If \(f\) has a local minimum on \(D\) at \({\bf x}^\star\), then \(H_{\bf x} \mathcal{L}({\bf \lambda},{\bf x})\) defined above is positive semi-definite on a linear constraint set \(\{v: Dg({\bf x}^\star)\cdot v = {\bf 0}\}\), that is
Fact (sufficient SOC)
Let \(f \colon \mathbb{R}^N \to \mathbb{R}\) and \(g \colon \mathbb{R}^N \to \mathbb{R}^K\) be twice continuously differentiable functions (\(C^2\)) and let \(D = U \cap \{ {\bf x} \colon g_i({\bf x}) = 0, i=1,\dots,K \}\) where \(U \subset \mathbb{R}^N\) is an open set.
Suppose there exists \({\bf x}^\star \in D\) such that \(\mathrm{rank}(Dg({\bf x}^\star)) = K\) and \(Df({\bf x}^\star) - \lambda^\star \cdot Dg({\bf x}^\star) = {\bf 0}\) for some \(\lambda^\star \in \mathbb{R}^K\) and the constraint qualification assumption holds at \({\bf x}^\star\) (FOC satisfied)
Then:
If \(H_{\bf x} \mathcal{L}({\bf \lambda},{\bf x})\) defined above is negative definite on a linear constraint set \(\{v: Dg({\bf x}^\star)\cdot v = {\bf 0}\}\), that is
then \({\bf x}^\star\) is the local constrained maximum of \(f\) on \(D\)
If \(H_{\bf x} \mathcal{L}({\bf \lambda},{\bf x})\) defined above is positive definite on a linear constraint set \(\{v: Dg({\bf x}^\star)\cdot v = {\bf 0}\}\), that is
then \({\bf x}^\star\) is the local constrained minimum of \(f\) on \(D\)
Thus, the structure of both the necessary and the sufficient conditions is very similar to the unconstrained case.
The important difference is that the definiteness of the Hessian is checked on the linear constraint set \(\{v: Dg({\bf x}^\star)\cdot v = {\bf 0}\}\) rather than on the whole \(\mathbb{R}^N\).
The linear constraint set represents the tangent hyperplane to the constraint set at \({\bf x}^\star\).
But how do we check for definiteness on a linear constraint set?
Definition
The Hessian of the Lagrangian with respect to \((\lambda, {\bf x})\) is caleld a bordered Hessian, and is given by
Similarly to the Hessian w.r.t. \({\bf x}\) above, we can derive the bordered Hessian using the rules of the differentiation from multivariate calculus, differentiating the gradient of the Lagrangian w.r.t. \((\lambda,{\bf x})\) which is given
the subscripts in the definition above denote the shape of the blocks in the bordered Hessian
some textbooks place the “border”, i.e. Jacobians of the constrained in upper left corner and the Hessian w.r.t. \({\bf x}\) of the objective in the lower right corner, with corresponding changes in the propositions below
the sign for the second term in the Lagrangian also appears and may differ between different texts
Definition
Consider a \(n \times n\) matrix \(A\) and let \(0 < k \le n\).
The leading principal minor of order \(k\) of \(A\) is the determinant of a matrix obtained from \(A\) by deleting its last \(n-k\) rows and columns.
Example
The leading principal minors of oder \(k = 1,\dots,n\) of \(A\) are
Fact
In the same settings as propositions above, namely for \(f \colon \mathbb{R}^N \to \mathbb{R}\) and \(g \colon \mathbb{R}^N \to \mathbb{R}^K\) twice continuously differentiable functions (\(C^2\)) and \(D = U \cap \{ {\bf x} \colon g_i({\bf x}) = 0, i=1,\dots,K \}\) where \(U \subset \mathbb{R}^N\) is an open.
\(H_{\bf x} \mathcal{L}({\bf \lambda},{\bf x})\) is negative semi-definite on a linear constraint set \(\{v: Dg({\bf x}^\star)\cdot v = {\bf 0}\}\) \(\iff\) the last \(N-K\) leading principal minors of \(H \mathcal{L}({\bf \lambda},{\bf x})\) are zero or alternate in sign, with the sign of the full Hessian matrix equal to \((-1)^N\).
\(H_{\bf x} \mathcal{L}({\bf \lambda},{\bf x})\) is positive semi-definite on a linear constraint set \(\{v: Dg({\bf x}^\star)\cdot v = {\bf 0}\}\) \(\iff\) the last \(N-K\) leading principal minors of \(H \mathcal{L}({\bf \lambda},{\bf x})\) are zero or have the same sign as \((-1)^K\).
\(H_{\bf x} \mathcal{L}({\bf \lambda},{\bf x})\) is negative definite on a linear constraint set \(\{v: Dg({\bf x}^\star)\cdot v = {\bf 0}\}\) \(\iff\) the last \(N-K\) leading principal minors of \(H \mathcal{L}({\bf \lambda},{\bf x})\) are non-zero and alternate in sign, with the sign of the full Hessian matrix equal to \((-1)^N\).
\(H_{\bf x} \mathcal{L}({\bf \lambda},{\bf x})\) is positive definite on a linear constraint set \(\{v: Dg({\bf x}^\star)\cdot v = {\bf 0}\}\) \(\iff\) the last \(N-K\) leading principal minors of \(H \mathcal{L}({\bf \lambda},{\bf x})\) are non-zero and have the same sign as \((-1)^K\).
Similarly to the unconstrained case, when none of the listed conditions for the bordered Hessian hold, it is indefinite and the point tested by the second order conditions is not a constrained optimizer.
Fact
Determinant of \(3 \times 3\) matrix can be computed by the triangles rule:
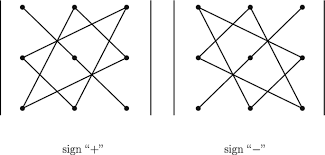
Example
Let’s check the second order conditions for the consumer choice problem.
Solving FOC we have as before
To check the second order conditions compute the Hessian at \({\bf x}^\star\)
Because \(N=2\) and \(K=1\) we need to check one last lead principle minor, which is the determinant of the whole \(H\mathcal{L}({\bf \lambda}^\star,{\bf x}^\star)\). Using the triangle rule for computing determinants of the \(3 \times 3\) matrix, we have
We have that the determinant of the bordered Hessian has the same sign as \((-1)^N\), and the condition for sign alternation is satisified for \(N-K = 1\) last leading principal minors.
Hence, \(H_{\bf x} \mathcal{L}({\bf \lambda},{\bf x})\) is negative definite, implying that \({\bf x}^\star\) is the local constrained maximum of \(f\) on \(D\) by the sufficient second order condition.
Lagrangian method: recipe#
Write down the Lagrangian function \(\mathcal{L}({\bf x},{\bf \lambda})\)
Find all stationary points of \(\mathcal{L}({\bf x},{\bf \lambda})\) with respect to \({\bf x}\) and \({\bf \lambda}\), i.e. solve the system of first order equations
Derive the bordered Hessian \(H \mathcal{L}({\bf x},{\bf \lambda})\) and compute it value at the stationary points
Using second order conditions, check if the stationary points are local optima
Compare the function values at all identified local optima to find the global one
in practice second order conditions (steps 3 and 4) may be skipped when for example the global shape of the function is known (convex case)
When does Lagrange method fail?#
Example
Proceed according to the Lagrange recipe
The FOC system of equations
does not have solutions! From second equation \(\lambda \ne 0\), then from the first equation \(x=0\), and so \(y=0\) from the thrid, but then the second equation is not satisfied.
However, we can deduce that \((x^\star,y^\star)=(0,0)\) is a maximizer in the following way. For all points \((x,y)\) which satisfy the constraint \(y^3 \ge 0\) because \(x^2 \ge 0\), and thus the maximum attainable value is \(f(x,y)=0\) which it takes at \((0,0)\).
Why does Lagrange method fail?
The Lagrange method fails because the constraint qualification assumption is not satisfied at \((0,0)\), i.e. the rank of Jacobian matrix of the constraints (one by two in this case) is zero which is less than the number of constraints \(K\).
Lagrange method may not work when:
Constraints qualification assumption is not satisfied at the stationary point
FOC system of equations does not have solutions (thus no local optima)
Saddle points – second order conditions can help
local optimizer is not a global one – no way to check without studying analytic properties of each problem
Conclusion: great tool, but blind application may lead to wrong results!
Inequality constraints and Kuhn-Tucker method#
Turning now to the inequality constrained optimization problems
Example
Maximization of utility subject to budget constraint
\(p_i\) is the price of good \(i\), assumed non-negative
\(m\) is the budget, assumed non-negative
\(\alpha>0\), \(\beta>0\)
Apply the Lagrange method neglecting the non-negativity requirement and assuming no money are wasted, and so the budget constraint binds:
Solving FOC, from the first equation we have \(\lambda = \alpha/p_1\), then from the second equation \(x_2 = \beta p_1/ \alpha p_2\) and from the third \(x_1 = m/p_1 -\beta/\alpha\). This is the only stationary point.
Hence, for some admissible parameter values, for example, \(\alpha=\beta=1\), \(p_1=p_2=1\) and \(m=0.4\) we can have the optimal level of consumption of good 1 to be negative!
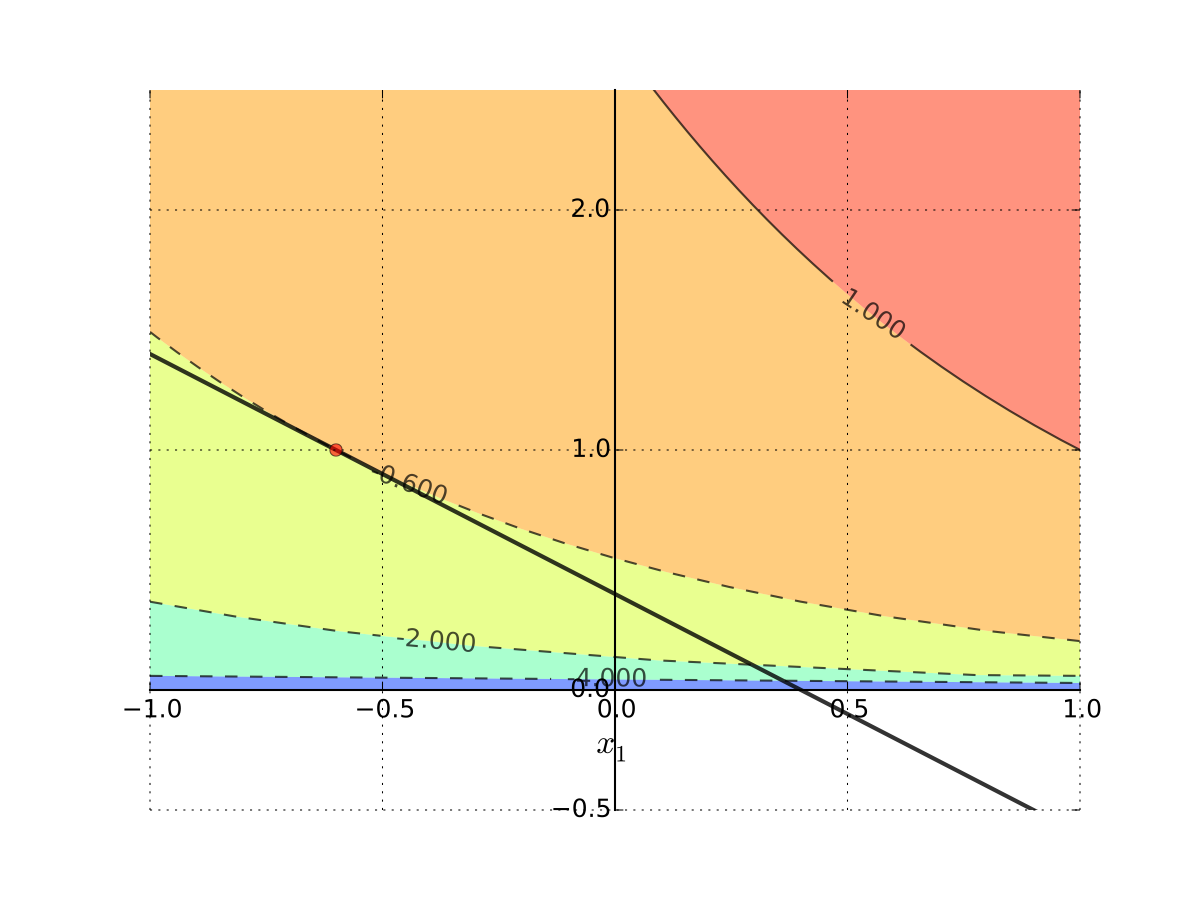
Fig. 103 Tangent point is infeasible#
Interpretation: No interior solution
Put differently
Every interior point on the budget line is dominated by the infeasible solution
Hence solution must be on the boundary
Since \(x_2 = 0\) implies \(x_1 + \log(x_2) = - \infty\), solution is
\(x_1^\star = 0\)
\(x_2^\star = m/p_2 = 0.4\)
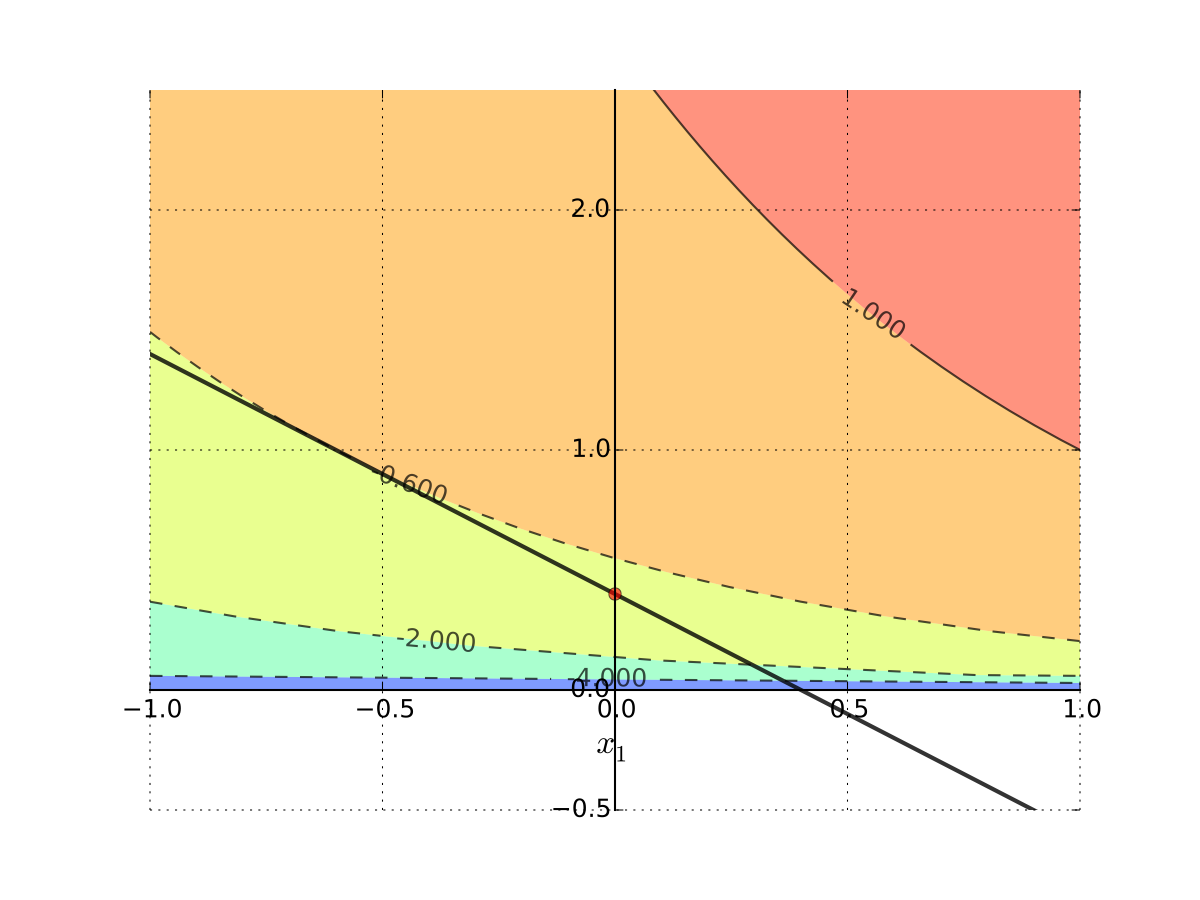
Fig. 104 Corner solution#
Let’s look at the systematic solution approach where the corner solutions will emerge naturally when they are optimal.
Karush-Kuhn-Tucker conditions (maximization)
Let \(f \colon \mathbb{R}^N \to \mathbb{R}\) and \(g \colon \mathbb{R}^N \to \mathbb{R}^K\) be continuously differentiable functions.
Let \(D = U \cap \{ {\bf x} \colon g_i({\bf x}) \le 0, i=1,\dots,K \}\) where \(U \subset \mathbb{R}^N\) is an open set.
Suppose that \({\bf x}^\star \in D\) is a local maximum of \(f\) on \(D\) and that the gradients of the constraint functions \(g_i\) corresponding to the binding constraints are linearly independent at \({\bf x}^\star\) (equivalently, the rank of the matrix composed of the gradients of the binding constraints is equal to the number of binding constraints).
Then there exists a vector \(\lambda^\star \in \mathbb{R}^K\) such that
and
Proof
See Sundaram 6.5
Karush-Kuhn-Tucker conditions (miminization)
In the settings of KKT conditions (maximization), suppose that \({\bf x}^\star \in D\) is a local minimum of \(f\) on \(D\) as before the matrix composed of the gradients of the binding constraints has full rank.
Then there exists a vector \(\lambda^\star \in \mathbb{R}^K\) such that (note opposite sign)
and
Very similar to the Lagrange theorem, but now we have inequalities!
The last set of conditions is called the complementary slackness conditions, and they play the following role:
if for a given \(i\) \(g_i({\bf x}^\star) = 0\), that is the \(i\)-th constraint is binding , then the corresponding \(\lambda_i^\star > 0\) acts as a Lagrange multiplier for an equality constraint
if on the other hand for a given \(i\) \(g_i({\bf x}^\star) < 0\), the corresponding \(\lambda_i^\star\) must be zero, removing the term with \(Dg_i({\bf x}^\star)\) from the first condition
This way the KKT conditions combine the unconstrained and equality constrained conditions in one
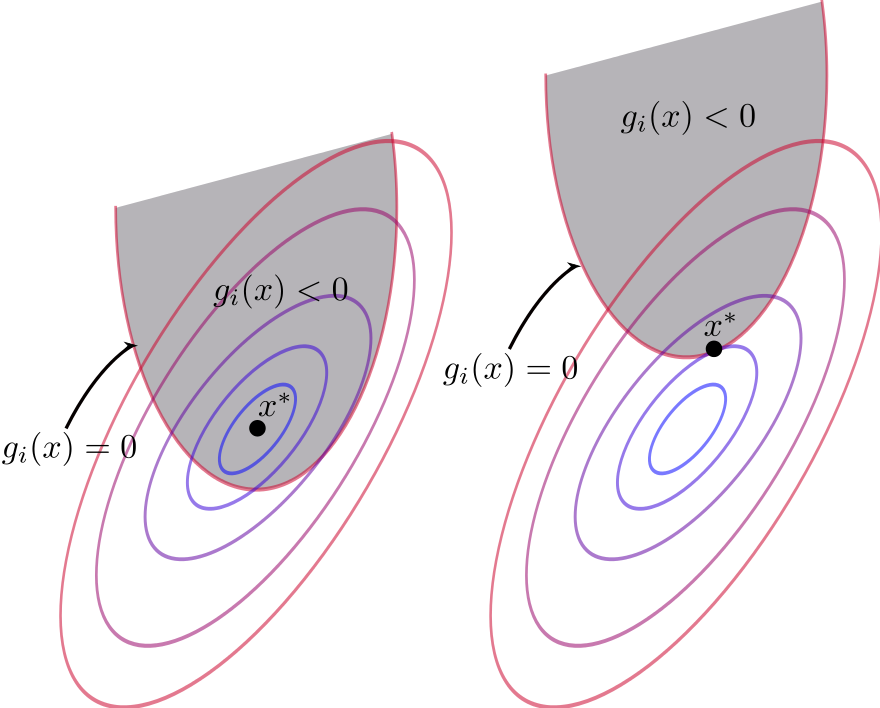
Fig. 105 Binding and non-binding constraint at \({\bf x}^\star\)#
Karush - Kuhn-Tucker method: recipe#
Essentially the same as for the Lagrange method
Write down the Lagrangian function \(\mathcal{L}({\bf x},{\bf \lambda})\)
Solve the KKT first order conditions to find the stationary points of \(\mathcal{L}({\bf x},{\bf \lambda})\) with respect to \({\bf x}\), together with the non-negativity of KKT multipliers and complementary slackness conditions
Using second order conditions using the subset of binding constraints, check if the stationary points at the boundary are local optima. Similarly, using the second order conditions for the unconstrained problem to investigate the interior stationary points
Compare the function values at all identified local optima to find the global one
Possible issues with KKT method are similar to the Lagrange method:
constraint qualification assumption
existence of constrained optima
local vs global optimality
Example
Returning to the utility maximization problem with budget constraint and non-negative consumption
Form the Lagrangian with 3 inequality constraints (have to flip the sign for non-negativity to stay within the general formulation)
The necessary KKT conditions are given by the following system of equations
The KKT conditions can be solved systematically by considering all combinations of the multipliers:
\(\lambda_1=\lambda_2=\lambda_3=0\)
The first equation becomes \(\alpha = 0\) which is inconsistent with the initially set \(\alpha>0\)\(\lambda_1=\lambda_2=0, \; \lambda_3>0 \implies x_1 p_1 + x_2 p_2 -m = 0\)
This is the exact case we looked at with the Lagrange method ignoring the non-negativity conditions on consumption. The solution is \(x_1^\star = \frac{m}{p_1} - \frac{\beta}{\alpha}\) and \(x_2^\star = \frac{\beta p_1}{\alpha p_2}\) if it also holds that \(x_1^\star >0\) and \(x_2^\star >0\), i.e. \(p_1/m < \alpha/\beta\)\(\lambda_1=\lambda_3=0, \; \lambda_2>0 \implies x_2 = 0\)
The case of \(x_2=0\) is outside of the domain of the utility function and could in fact be excluded from the start.\(\lambda_1=0, \;\lambda_2>0, \; \lambda_3>0 \implies x_2 = x_1\) and \(p_1 + x_2 p_2 -m = 0\)
Inconsistent similarly to the previous case\(\lambda_1>0, \;\lambda_2 = \lambda_3 = 0 \implies x_1 = 0\)
The second equation becomes \(\beta / x_2 = 0\) which is inconsistent with the \(\beta>0\) and \(x_2 \ne 0\)\(\lambda_1>0, \;\lambda_2 = 0, \; \lambda_3 > 0 \implies x_1 = 0\) and \(p_1 + x_2 p_2 -m = 0\)
We have the following system in this case
From the last equation \(x_2 = m/p_2\), combining the two last equations \(\lambda_3 = \beta/m\), and from the first equation \(\lambda_1 = \beta p_1/m - \alpha\). The solution holds conditional on \(\lambda_1>0\), i.e. \(p_1/m > \alpha/\beta\).
\(\lambda_1>0, \;\lambda_2 > 0, \; \lambda_3 = 0 \implies x_1 = 0\) and \(x_2 = 0\)
Inconsistent similar to case 3\(\lambda_1>0, \;\lambda_2 > 0, \; \lambda_3 > 0 \implies x_1 = x_2 = p_1 + x_2 p_2 -m = 0\)
Inconsistent similarly to the previous case
To summarize, the solution to the KKT conditions is given by the following cases (it’s easy to see that the two solutions coincide for the equality in the parameter condition):
Thus, the corner solution is included in the solution set of the KKT conditions.
Second order conditions#
Nearly identical to the secondary order conditions in the equality constraints case, except written only for the constraints which are binding/active at \({\bf x}^\star\) under consideration.
Example
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
f = lambda x: x[0]**3/3 - 3*x[1]**2 + 5*x[0] - 6*x[0]*x[1]
x = y = np.linspace(-10.0, 10.0, 100)
X, Y = np.meshgrid(x, y)
zs = np.array([f((x,y)) for x,y in zip(np.ravel(X), np.ravel(Y))])
Z = zs.reshape(X.shape)
a,b=4,8
# (x/a)^2 + (y/b)^2 = 1
theta = np.linspace(0, 2 * np.pi, 100)
X1 = a*np.cos(theta)
Y1 = b*np.sin(theta)
zs = np.array([f((x,y)) for x,y in zip(np.ravel(X1), np.ravel(Y1))])
Z1 = zs.reshape(X1.shape)
fig = plt.figure(dpi=160)
ax2 = fig.add_subplot(111)
ax2.set_aspect('equal', 'box')
ax2.contour(X, Y, Z, 50,
cmap=cm.jet)
ax2.plot(X1, Y1)
plt.setp(ax2, xticks=[],yticks=[])
fig = plt.figure(dpi=160)
ax3 = fig.add_subplot(111, projection='3d')
ax3.plot_wireframe(X, Y, Z,
rstride=2,
cstride=2,
alpha=0.7,
linewidth=0.25)
f0 = f(np.zeros((2)))+0.1
ax3.plot(X1, Y1, Z1, c='red')
plt.setp(ax3,xticks=[],yticks=[],zticks=[])
ax3.view_init(elev=18, azim=154)
plt.show()

Extra material#
Story of William Karush and his contribution the KKT theorem by Richard W Cottle (download pdf)