Announcements & Reminders
Quiz 2
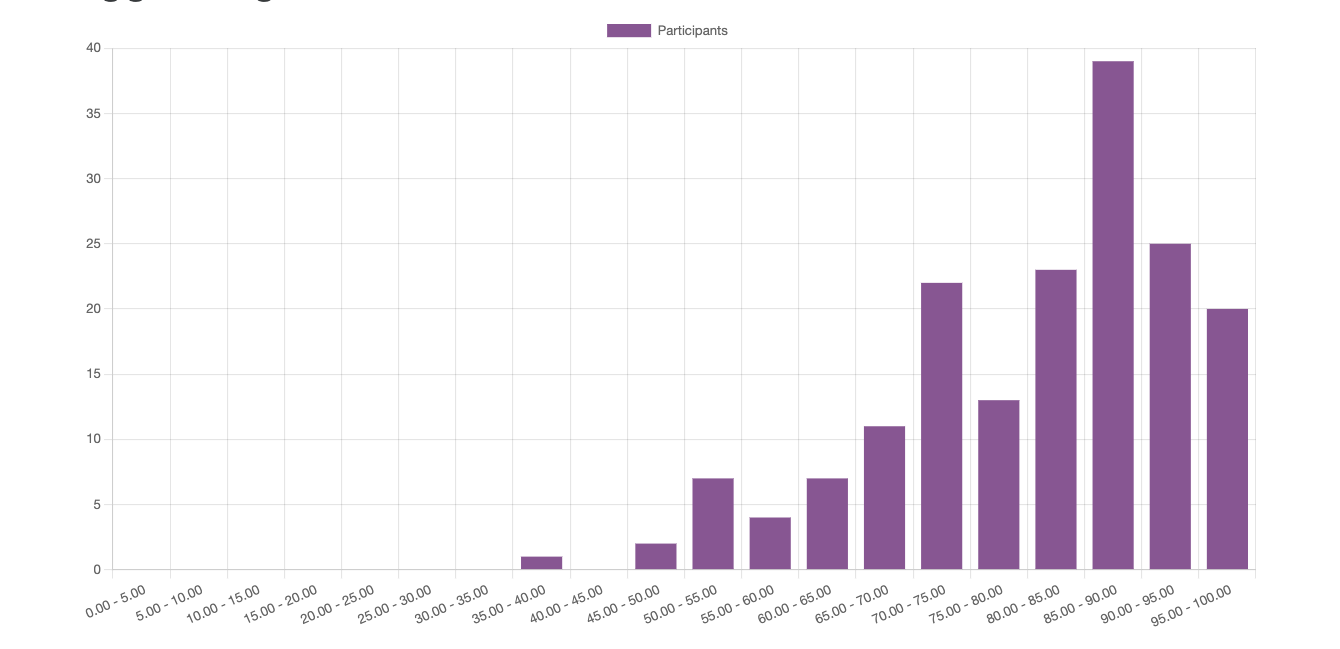
Fig. 51 Distribution of results for Quiz 2#
The midterm is scheduled at 18:30 to 19:45 (1 hour + 15 min reading time) on Monday, April 15 in Melville Hall
Practice problems for the midterm to be published
SPECIAL NOTE
The material in this section of the lecture notes will be used in the quiz 3, however, the midterm and the final exams will not target detailed knowledge of this section. The exams will however require a practical knowledge of linear algebra needed for solving problems similar to the tutorial problems.
📖 Elements of linear algebra#
⏱ | words
Important note
This lecture covers the fundamental concepts of linear algebra, and covers more material than the time permits to cover in a single lecture
It is strongly advised to study the details of this lecture note is greater details in preparation for the midterm and final exams
I also encourage you to watch some or all of the videos in the 3Blue1Brown: Essence of linear algebra series at your own time to get deeper understanding of the linear algebra concepts through visualizations and excellent explanations
The lecture covers the following main concepts:
Vector space
Linear combination
Span
Linear independence
Basis and dimension
Matrices as linear transformations
Column spaces and null space
Rank of a matrix
Singular matrices
Matrix determinant
Eigenvectors and eigenvalues
Diagonalization of matrices
See references in the bottom of this note
Midterm and final exam may have some but not much of the material from this lecture because it is mainly left for self-study. Open book quiz, however, will contain questions for this material.
Motivating example#
Linear algebra is most useful in economics for solving systems of linear equations
Definition
A general system of linear equations can be written as
More often we write the system in matrix form
Let’s solve this system on a computer:
import numpy as np
from scipy.linalg import solve
A = [[0, 2, 4],
[1, 4, 8],
[0, 3, 7]]
b = (1, 2, 0)
A, b = np.asarray(A), np.asarray(b)
x=solve(A, b)
print(f'Solutions is x={x}')
Solutions is x=[-1.77635684e-15 3.50000000e+00 -1.50000000e+00]
This tells us that the solution is \(x = (0. , 3.5, -1.5)\)
That is,
The usual question: if computers can do it so easily — what do we need to study for?
But now let’s try this similar looking problem
Question: what changed?
import numpy as np
from scipy.linalg import solve
A = [[0, 2, 4],
[1, 4, 8],
[0, 3, 6]]
b = (1, 2, 0)
A, b = np.asarray(A), np.asarray(b)
x=solve(A, b)
print(f'Solutions is x={x}')
Solutions is x=[ 0.00000000e+00 -9.00719925e+15 4.50359963e+15]
/var/folders/5d/cjhpvdlx7lg8zt1ypw5fcyy40000gn/T/ipykernel_31662/3978225594.py:8: LinAlgWarning: Ill-conditioned matrix (rcond=4.11194e-18): result may not be accurate.
x=solve(A, b)
This is the output that we get:
LinAlgWarning: Ill-conditioned matrix
What does this mean?
How can we fix it?
We still need to understand the concepts after all!
Vector Space#
Definition
A field (of numbers) is a set \(\mathbb{F}\) of numbers with the property that if \(a,b \in \mathbb{F}\), then \(a+b\), \(a-b\), \(ab\) and \(a/b\) (provided that \(b \ne 0\)) are also in \(\mathbb{F}\).
Example
\(\mathbb{Q}\) and \(\mathbb{R}\) are fields, but \(\mathbb{N}\), \(\mathbb{Z}\) is not (why?)
Definition
A vector space over a field \(\mathbb{F}\) is a set \(V\) of objects called vectors, together with two operations:
vector addition that takes two vectors \(v,w \in V\) and produces a vector \(v+w \in V\), and
scalar multiplication that takes a scalar \(\alpha \in \mathbb{F}\) and a vector \(v \in V\) and produces a vector \(\alpha v \in V\),
which satisfy the following properties:
Associativity of vector addition: \((u+v)+w = u+ (v+w)\) for all \(u,v,w \in V\)
Existance of zero vector \({\bf 0}\) such that \(v + {\bf 0} = v\) for all \(v \in V\)
Existance of negatives: for each \(v \in V\) there exists a vector \(-v \in V\) such that \(v + (-v) = {\bf 0}\)
Associativity of multiplication: \(\alpha (\beta v) = (\alpha \beta) v\) for all \(\alpha, \beta \in \mathbb{F}\) and \(v \in V\)
Distributivity: \((\alpha + \beta) v = \alpha v + \beta v\) and \(\alpha(v+w) = \alpha v + \alpha w\) for all \(\alpha, \beta \in \mathbb{F}\) and \(v, w \in V\)
Unitarity: \(1u = u\) for all \(u \in V\)
may seem like a bunch of abstract nonsense, but it’s actually describes something intuitive
what we already know about operations with vectors in \(\mathbb{R}^N\) put in formal definition
Example
Example

Fig. 52 Scalar multiplication by a negative number#
Dot product and norm#
Definition
The dot product of two vectors \(x, y \in \mathbb{R}^N\) is
The notation \(\square^T\) flips the vector from column-vector to row-vector, this will make sense when we talk later about matrices for which vectors are special case.
Fact: Properties of dot product
For any \(\alpha, \beta \in \mathbb{R}\) and any \(x, y \in \mathbb{R}^N\), the following statements are true:
\(x^T y = y^T x\)
\((\alpha x)' (\beta y) = \alpha \beta (x^T y)\)
\(x^T (y + z) = x^T y + x^T z\)
Definition
The (Euclidean) norm of \(x \in \mathbb{R}^N\) is defined as
\(\| x \|\) represents the ``length’’ of \(x\)
\(\| x - y \|\) represents distance between \(x\) and \(y\)
Fact
For any \(\alpha \in \mathbb{R}\) and any \(x, y \in \mathbb{R}^N\), the following statements are true:
\(\| x \| \geq 0\) and \(\| x \| = 0\) if and only if \(x = 0\)
\(\| \alpha x \| = |\alpha| \| x \|\)
\(\| x + y \| \leq \| x \| + \| y \|\) (triangle inequality)
\(| x^T y | \leq \| x \| \| y \|\) (Cauchy-Schwarz inequality)
Linear combinations#
Definition
A linear combination of vectors \(x_1,\ldots, x_K\) in \(\mathbb{R}^N\) is a vector
where \(\alpha_1,\ldots, \alpha_K\) are scalars
Example
Fact
Inner products of linear combinations satisfy
Proof
Follows from the properties of the dot product after some simple algebra
Span#
Let \(X \subset \mathbb{R}^N\) be any nonempty set (of points in \(\mathbb{R}^N\), i.e. vectors)
Definition
Set of all possible linear combinations of elements of \(X\) is called the span of \(X\), denoted by \(\mathrm{span}(X)\)
For finite \(X = \{x_1,\ldots, x_K\}\) the span can be expressed as
Example
Let’s start with the span of a singleton
Let \(X = \{ (1,1) \} \subset \mathbb{R}^2\)
The span of \(X\) is all vectors of the form
Constitutes a line in the plane that passes through
the vector \((1,1)\) (set \(\alpha = 1\))
the origin \((0,0)\) (set \(\alpha = 0\))
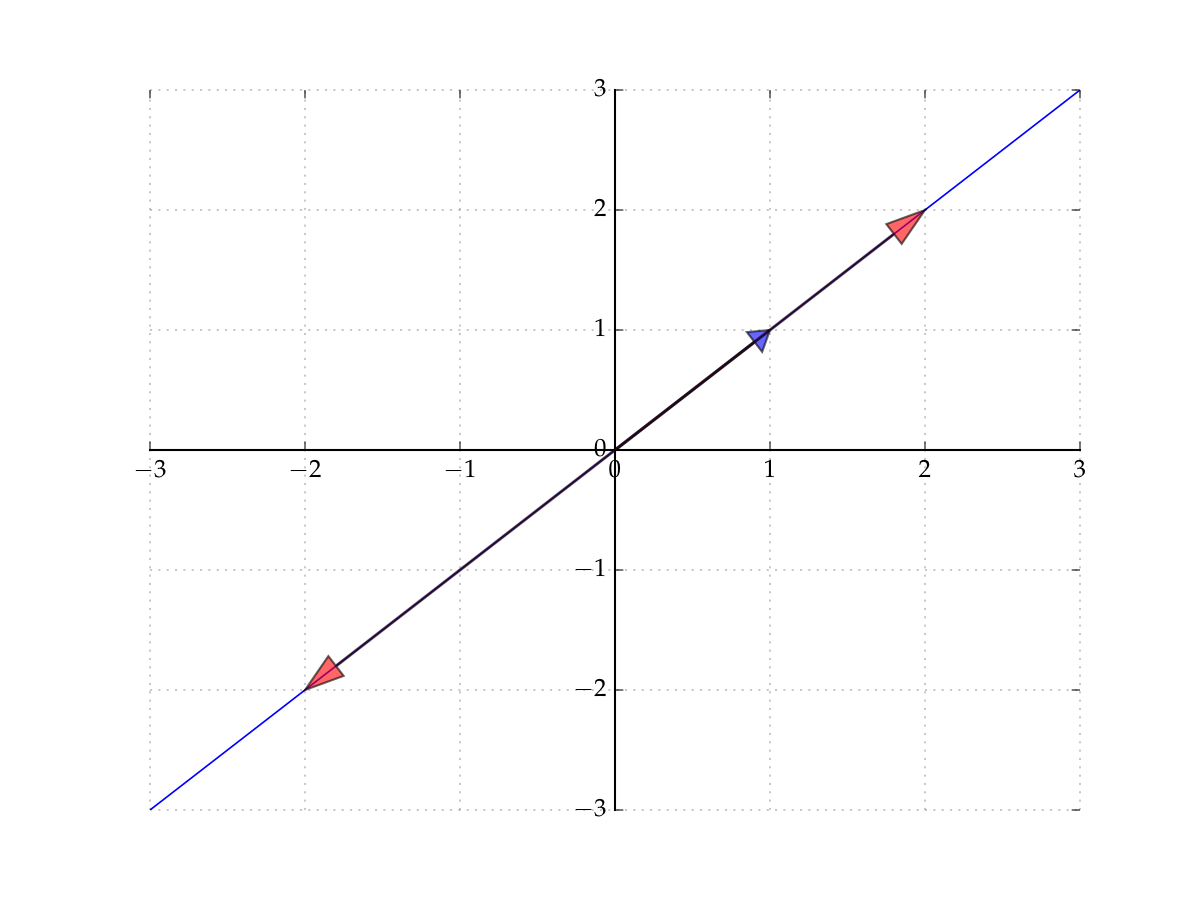
Fig. 53 The span of \((1,1)\) in \(\mathbb{R}^2\)#
Example
Let \(x_1 = (3, 4, 2)\) and let \(x_2 = (3, -4, 0.4)\)
By definition, the span is all vectors of the form
It turns out to be a plane that passes through
the vector \(x_1\)
the vector \(x_2\)
the origin \(0\)
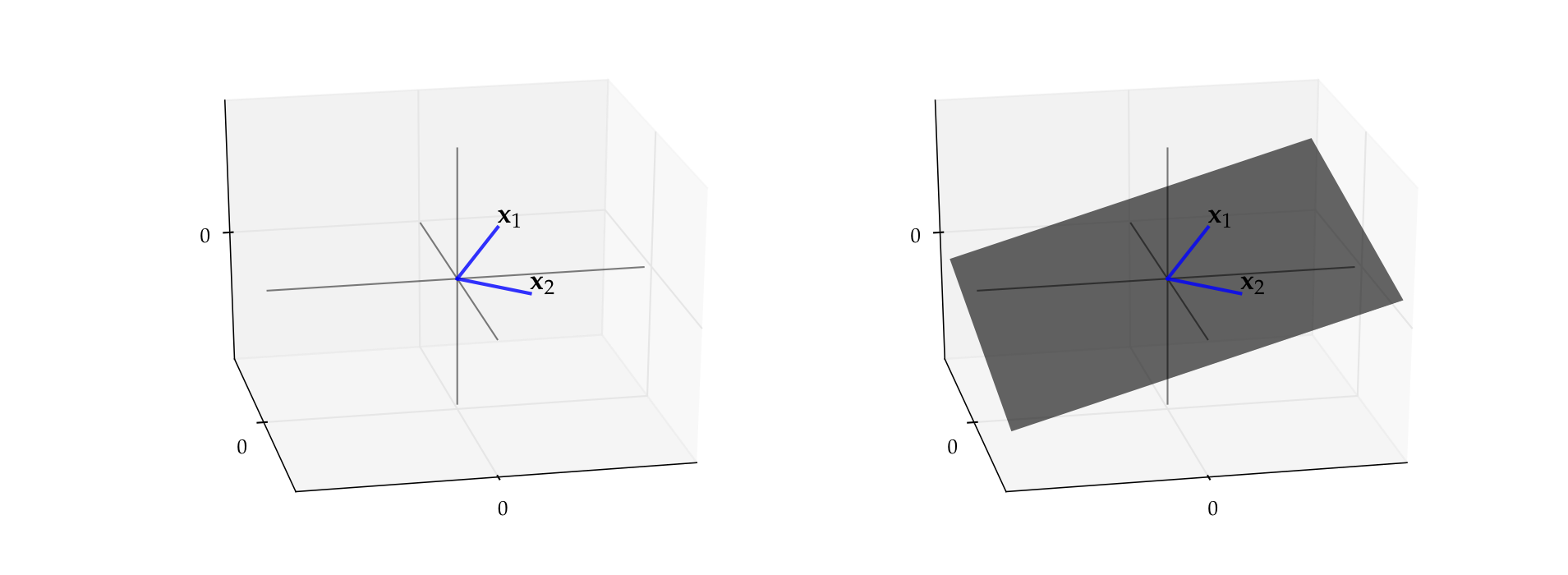
Fig. 54 Span of \(x_1, x_2\)#
Definition
Consider the vectors \(\{e_1, \ldots, e_N\} \subset \mathbb{R}^N\), where
That is, \(e_n\) has all zeros except for a \(1\) as the \(n\)-th element
Vectors \(e_1, \ldots, e_N\) are called the canonical basis vectors of \(\mathbb{R}^N\)
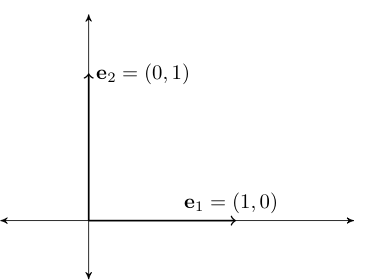
Fig. 55 Canonical basis vectors in \(\mathbb{R}^2\)#
Fact
The span of \(\{e_1, \ldots, e_N\}\) is equal to all of \(\mathbb{R}^N\)
Proof
Proof for \(N=2\):
Pick any \(y \in \mathbb{R}^2\)
We have
Thus, \(y \in \mathrm{span} \{e_1, e_2\}\)
Since \(y\) arbitrary, we have shown that \(\mathrm{span} \{e_1, e_2\} = \mathbb{R}^2\)
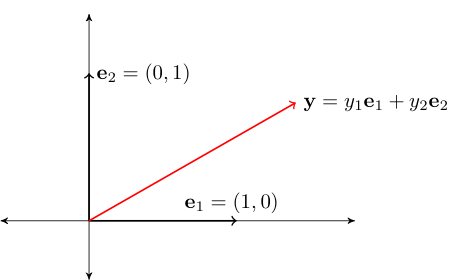
Fig. 56 Canonical basis vectors in \(\mathbb{R}^2\)#
Linear subspace#
Definition
A nonempty \(S \subset \mathbb{R}^N\) called a linear subspace of \(\mathbb{R}^N\) if
In other words, \(S \subset \mathbb{R}^N\) is “closed” under vector addition and scalar multiplication
Note: Sometimes we just say subspace and drop “linear”
Example
\(\mathbb{R}^N\) itself is a linear subspace of \(\mathbb{R}^N\)
Fact
Fix \(a \in \mathbb{R}^N\) and let \(A = \{ x \in \mathbb{R}^N \colon a 'x = 0 \}\)
The set \(A\) is a linear subspace of \(\mathbb{R}^N\)
Proof
Let \(x, y \in A\) and let \(\alpha, \beta \in \mathbb{R}\)
We must show that \(z = \alpha x + \beta y \in A\)
Equivalently, that \(a^T z = 0\)
True because
Linear independence#
Definition
A nonempty collection of vectors \(X = \{x_1,\ldots, x_K\} \subset \mathbb{R}^N\) is called linearly independent if
linear independence of a set of vectors determines how large a space they span
loosely speaking, linearly independent sets span large spaces
Example
Let \(x = (1, 2)\) and \(y = (-5, 3)\)
The set \(X = \{x, y\}\) is linearly independent in \(\mathbb{R}^2\)
Indeed, suppose \(\alpha_1\) and \(\alpha_2\) are scalars with
Equivalently,
Then \(2(5\alpha_2) = 10 \alpha_2 = -3 \alpha_2\), implying \(\alpha_2 = 0\) and hence \(\alpha_1 = 0\)
Fact
The set of canonical basis vectors \(\{e_1, \ldots, e_N\}\) is linearly independent in \(\mathbb{R}^N\)
Proof
Let \(\alpha_1, \ldots, \alpha_N\) be coefficients such that \(\sum_{k=1}^N \alpha_k e_k = 0\)
Then
In particular, \(\alpha_k = \) for all \(k\)
Hence \(\{e_1, \ldots, e_N\}\) linearly independent
\(\blacksquare\)
Fact
Take \(X = \{x_1,\ldots, x_K\} \subset \mathbb{R}^N\). For \(K > 1\) all of following statements are equivalent
\(X\) is linearly independent
No \(x_i \in X\) can be written as linear combination of the others
\(X_0 \subset X \implies \mathrm{span}(X_0) \subset \mathrm{span}(X)\)
Example
As another visual example of linear independence, consider the pair
The span of this pair is a plane in \(\mathbb{R}^3\)
But if we drop either one the span reduces to a line
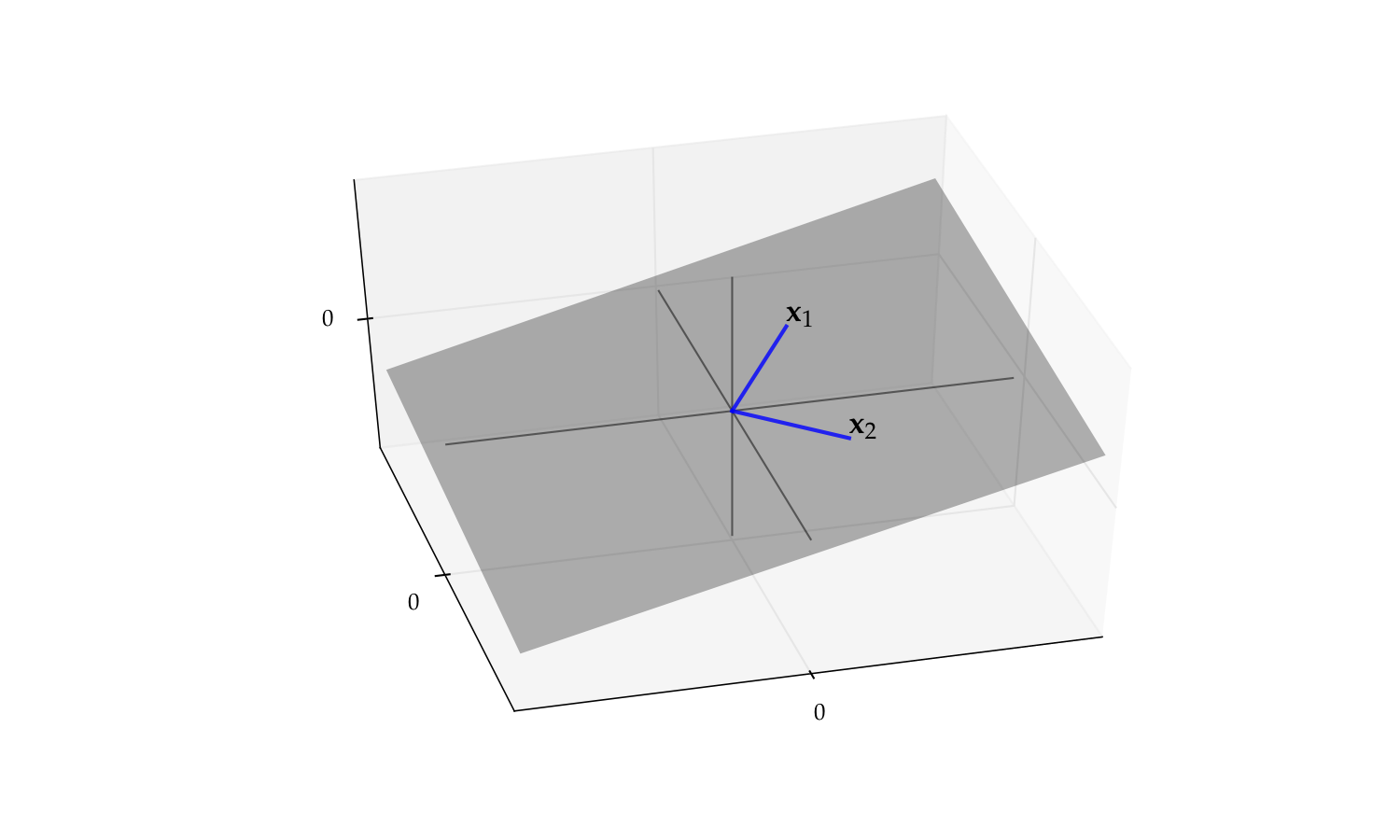
Fig. 57 The span of \(\{x_1, x_2\}\) is a plane#
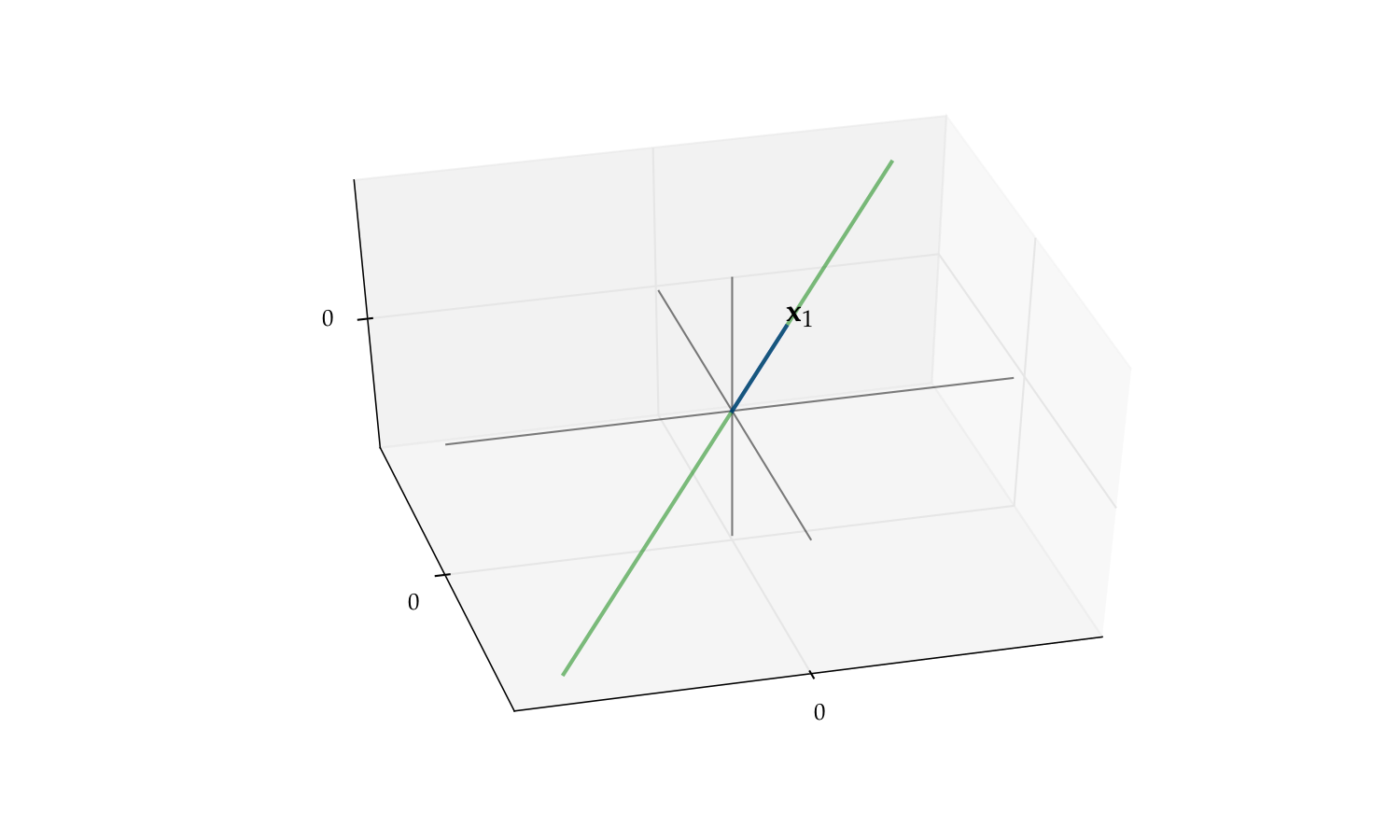
Fig. 58 The span of \(\{x_1\}\) alone is a line#
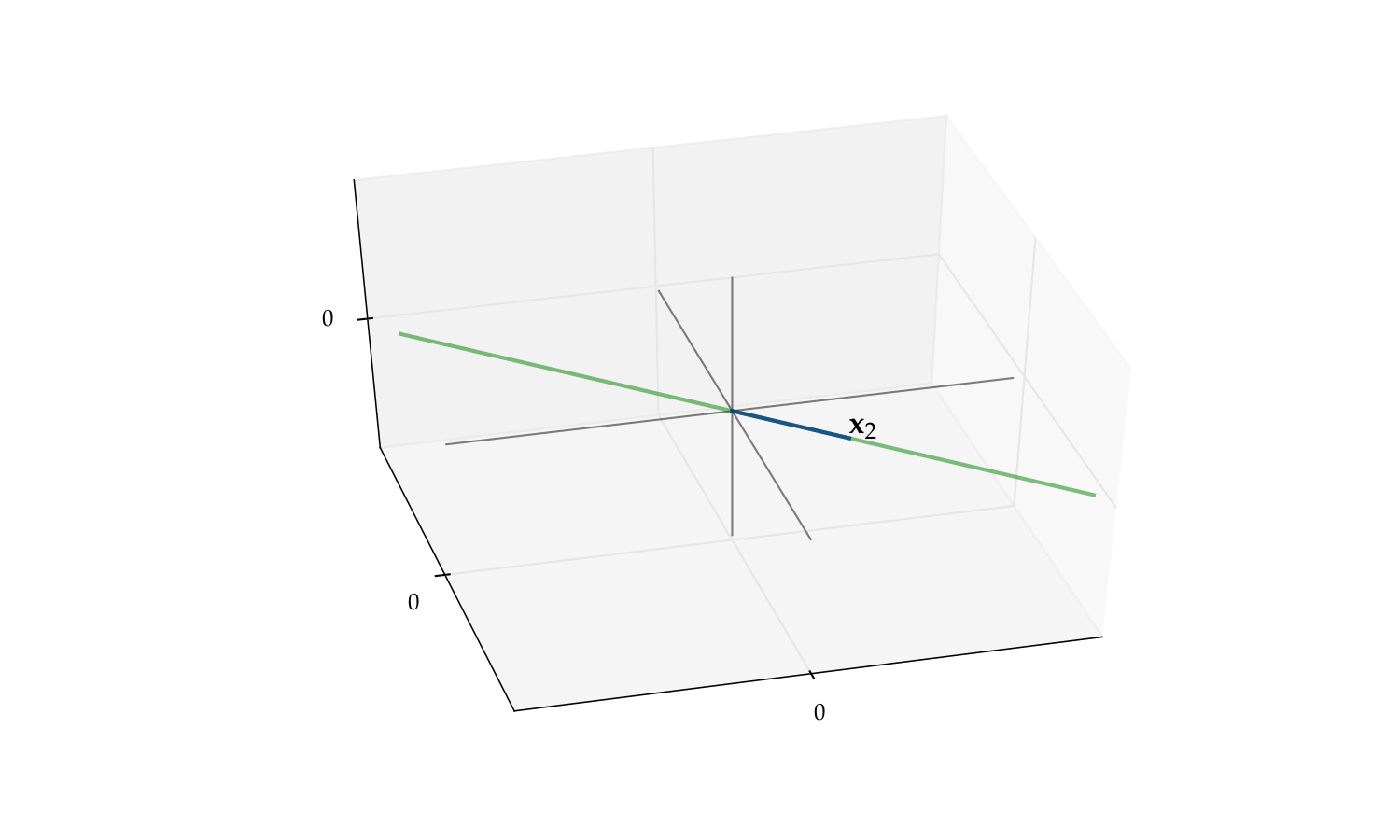
Fig. 59 The span of \(\{x_2\}\) alone is a line#
Fact
If \(X\) is linearly independent, then \(X\) does not contain \(0\)
Proof
Exercise
Fact
If \(X\) is linearly independent, then every subset of \(X\) is linearly independent
Proof
Sketch of proof: Suppose for example that \(\{x_1,\ldots, x_{K-1}\} \subset X\) is linearly dependent
Then \(\exists \; \alpha_1, \ldots, \alpha_{K-1}\) not all zero with \(\sum_{k=1}^{K-1} \alpha_k x_k = 0\)
Setting \(\alpha_K =0\) we can write this as \(\sum_{k=1}^K \alpha_k x_k = 0\)
Not all scalars zero so contradicts linear independence of \(X\)
Fact
If \(X= \{x_1,\ldots, x_K\} \subset \mathbb{R}^N\) is linearly independent and \(z\) is an \(N\)-vector not in \(\mathrm{span}(X)\), then \(X \cup \{ z \}\) is linearly independent
Proof
Suppose to the contrary that \(X \cup \{ z \}\) is linearly dependent:
If \(\beta=0\), then we have \(\sum_{k=1}^K \alpha_k x_k = 0\) and \(\alpha_k \ne 0\) for some \(k\), a contradiction
If \(\beta \ne0\), then by we have
Hence \(z \in \mathrm{span}(X)\) — contradiction
Fact
If \(X = \{x_1,\ldots, x_K\} \subset \mathbb{R}^N\) is linearly independent and \(y \in \mathbb{R}^N\), then there is at most one set of scalars \(\alpha_1,\ldots,\alpha_K\) such that \(y = \sum_{k=1}^K \alpha_k x_k\)
Proof
Suppose there are two such sets of scalars
That is,
Here’s one of the most fundamental results in linear algebra
Exchange Lemma
Let \(S\) be a linear subspace of \(\mathbb{R}^N\), and be spanned by \(K\) vectors.
Then any linearly independent subset of \(S\) has at most \(K\)
vectors
Proof
Omitted
Example
If \(X = \{x_1, x_2, x_3\} \subset \mathbb{R}^2\), then \(X\) is linearly dependent
because \(\mathbb{R}^2\) is spanned by the two vectors \(e_1, e_2\)
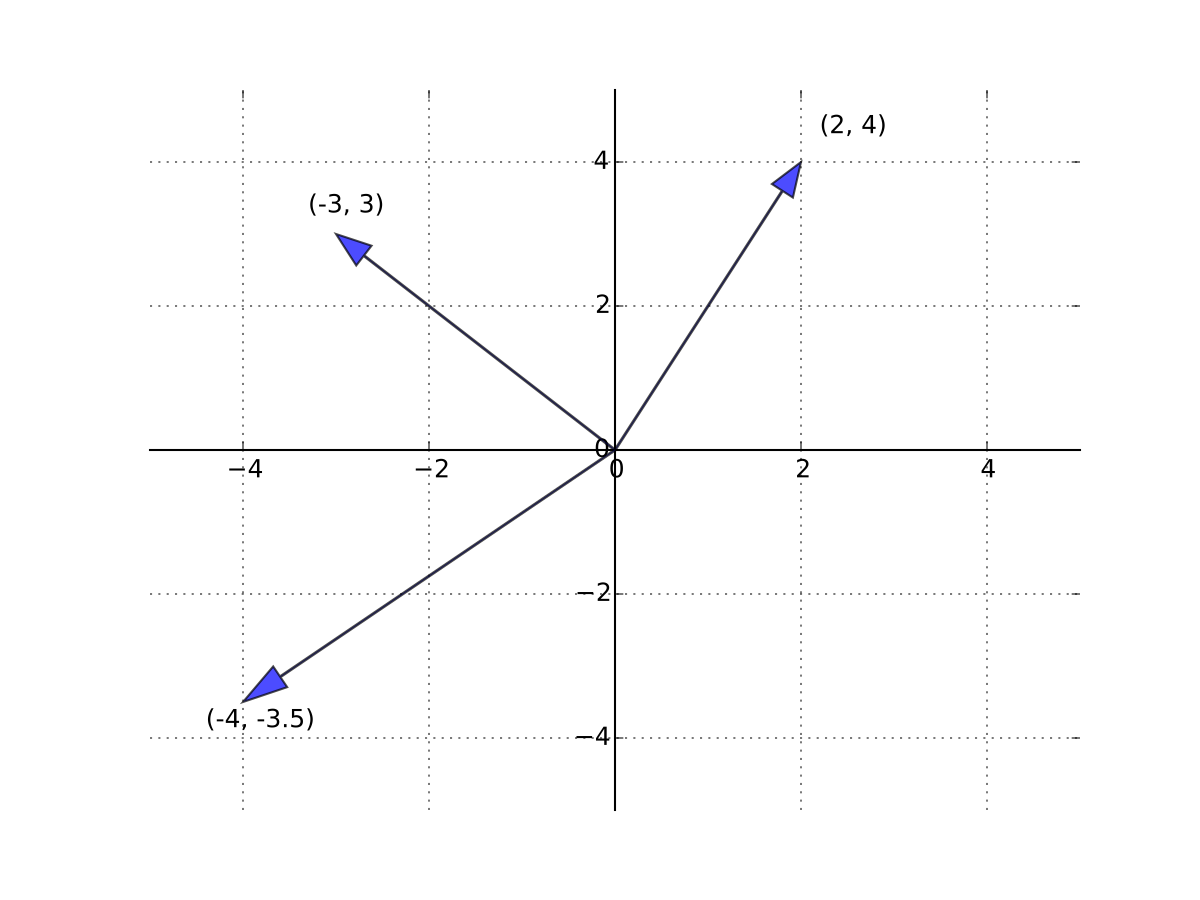
Fig. 60 Must be linearly dependent#
Fact
Let \(X = \{ x_1, \ldots, x_N \}\) be any \(N\) vectors in \(\mathbb{R}^N\)
\(\mathrm{span}(X) = \mathbb{R}^N\) if and only if \(X\) is linearly independent
Example
The vectors \(x = (1, 2)\) and \(y = (-5, 3)\) span \(\mathbb{R}^2\)
Proof
Let prove that
\(X= \{ x_1, \ldots, x_N \}\) linearly independent \(\implies\) \(\mathrm{span}(X) = \mathbb{R}^N\)
Seeking a contradiction, suppose that
\(X \) is linearly independent
and yet \(\exists \, z \in \mathbb{R}^N\) with \(z \notin \mathrm{span}(X)\)
But then \(X \cup \{z\} \subset \mathbb{R}^N\) is linearly independent (why?)
This set has \(N+1\) elements
And yet \(\mathbb{R}^N\) is spanned by the \(N\) canonical basis vectors
Contradiction (of what?)
Next let’s show the converse
\(\mathrm{span}(X) = \mathbb{R}^N\) \(\implies\) \(X= \{ x_1, \ldots, x_N \}\) linearly independent
Seeking a contradiction, suppose that
\(\mathrm{span}(X) = \mathbb{R}^N\)
and yet \(X\) is linearly dependent
Since \(X\) not independent, \(\exists X_0 \subsetneq X\) with \(\mathrm{span}(X_0) = \mathrm{span}(X)\)
But by 1 this implies that \(\mathbb{R}^N\) is spanned by \(K < N\) vectors
But then the \(N\) canonical basis vectors must be linearly dependent
Contradiction
Bases and dimension#
Definition
Let \(S\) be a linear subspace of \(\mathbb{R}^N\)
A set of vectors \(B = \{b_1, \ldots, b_K\} \subset S\) is called a basis of \(S\) if
\(B\) is linearly independent
\(\mathrm{span}(B) = S\)
Example
Canonical basis vectors form a basis of \(\mathbb{R}^N\)
Example
Recall the plane
We showed before that \(\mathrm{span}\{e_1, e_2\} = P\) for
Moreover, \(\{e_1, e_2\}\) is linearly independent (why?)
Hence \(\{e_1, e_2\}\) is a basis for \(P\)
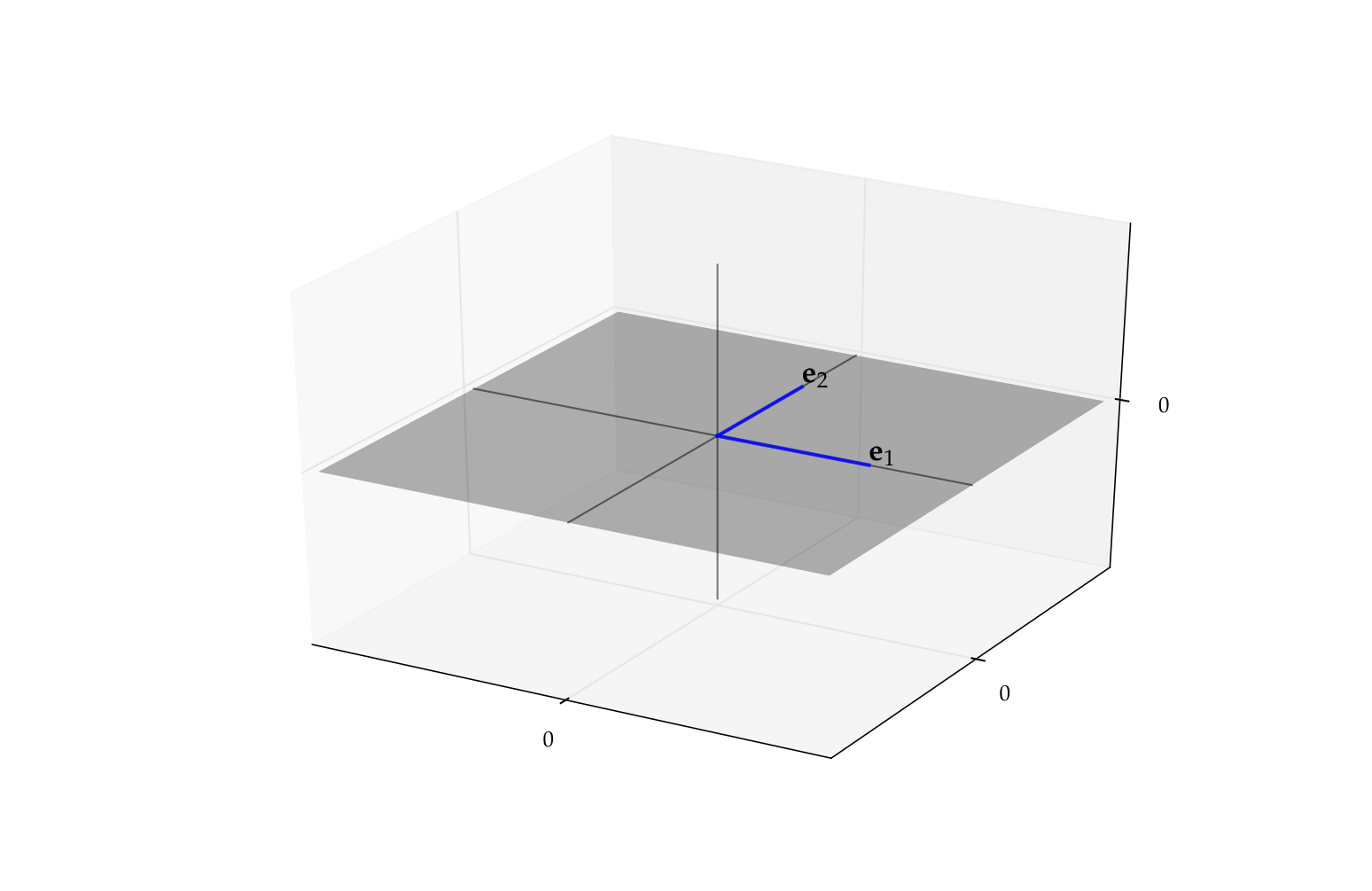
Fig. 61 The pair \(\{e_1, e_2\}\) form a basis for \(P\)#
What are the implications of \(B\) being a basis of \(S\)?
every element of \(S\) can be represented uniquely from the smaller set \(B\)
In more detail:
\(B\) spans \(S\) and, by linear independence, every element is needed to span \(S\) — a “minimal” spanning set
Since \(B\) spans \(S\), every \(y\) in \(S\) can be represented as a linear combination of the basis vectors
By independence, this representation is unique
Fact
If \(B \subset \mathbb{R}^N\) is linearly independent, then \(B\) is a basis of \(\mathrm{span}(B)\)
Proof
Follows from the definitions
Fact: Fundamental Properties of Bases
If \(S\) is a linear subspace of \(\mathbb{R}^N\) distinct from \(\{0\}\), then
\(S\) has at least one basis, and
every basis of \(S\) has the same number of elements
Proof
Proof of part 2: Let \(B_i\) be a basis of \(S\) with \(K_i\) elements, \(i=1, 2\)
By definition, \(B_2\) is a linearly independent subset of \(S\)
Moreover, \(S\) is spanned by the set \(B_1\), which has \(K_1\) elements
Hence \(K_2 \leq K_1\)
Reversing the roles of \(B_1\) and \(B_2\) gives \(K_1 \leq K_2\)
Definition
Let \(S\) be a linear subspace of \(\mathbb{R}^N\)
We now know that every basis of \(S\) has the same number of elements
This common number is called the dimension of \(S\)
Example
\(\mathbb{R}^N\) is \(N\) dimensional because the \(N\) canonical basis vectors form a basis
Example
\(P = \{ (x_1, x_2, 0) \in \mathbb{R}^3 \colon x_1, x_2 \in \mathbb{R \}}\) is two dimensional because the first two canonical basis vectors of \(\mathbb{R}^3\) form a basis
Linear Mappings#
Linear functions are in one-to-one correspondence with matrices
Nonlinear functions are closely connected to linear functions through Taylor approximation
Definition
A function \(T \colon \mathbb{R}^K \to \mathbb{R}^N\) is called linear if
Linear functions often written with upper case letters
Typically omit parenthesis around arguments when convenient
Example
\(T \colon \mathbb{R} \to \mathbb{R}\) defined by \(Tx = 2x\) is linear
Proof
Take any \(\alpha, \beta, x, y\) in \(\mathbb{R}\) and observe that
Example
The function \(f \colon \mathbb{R} \to \mathbb{R}\) defined by \(f(x) = x^2\) is nonlinear
Proof
Set \(\alpha = \beta = x = y = 1\)
Then
\(f(\alpha x + \beta y) = f(2) = 4\)
But \(\alpha f(x) + \beta f(y) = 1 + 1 = 2\)
Example
Given constants \(c_1\) and \(c_2\), the function \(T \colon \mathbb{R}^2 \to \mathbb{R}\) defined by
is linear
Proof
If we take any \(\alpha, \beta\) in \(\mathbb{R}\) and \(x, y\) in \(\mathbb{R}^2\), then
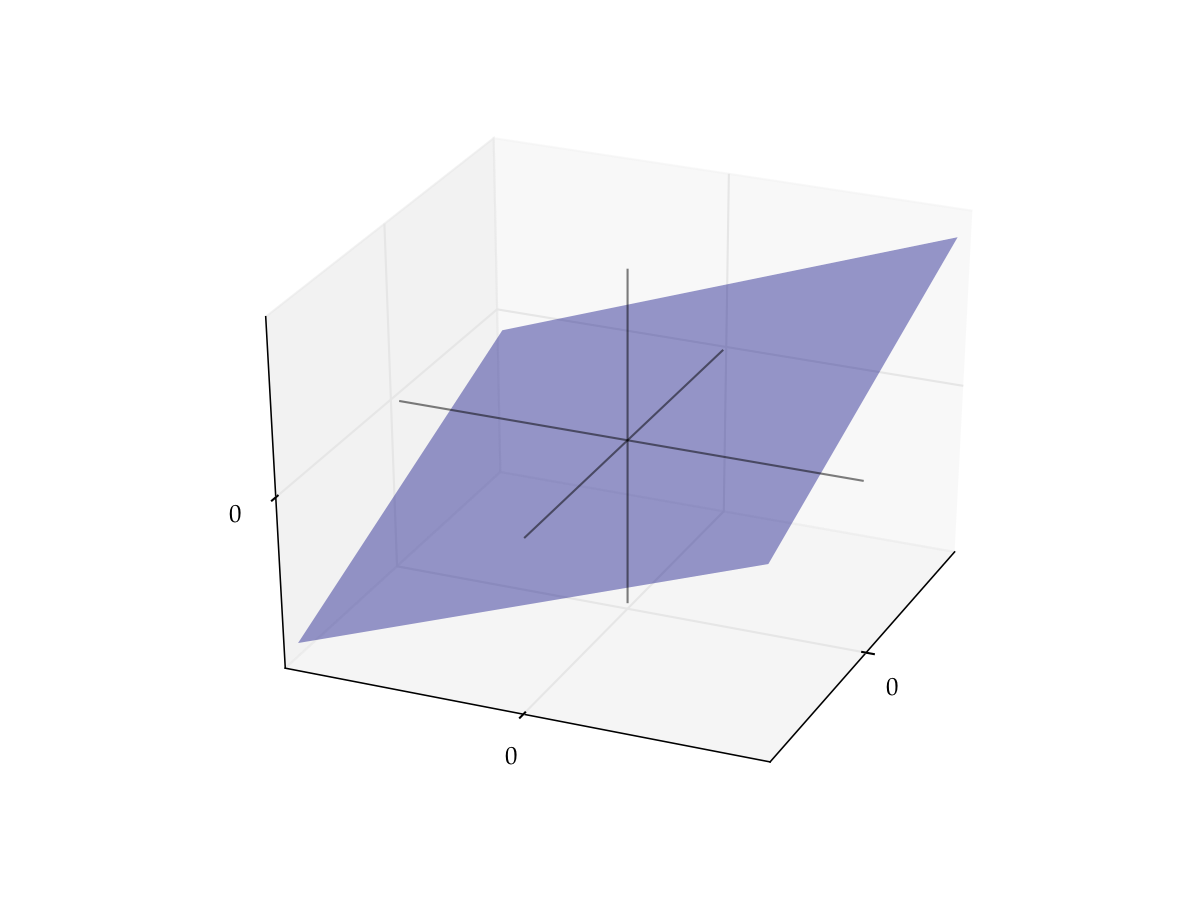
Fig. 62 The graph of \(T x = c_1 x_1 + c_2 x_2\) is a plane through the origin#
Note
Thinking of linear functions as those whose graph is a straight line is not correct!
Example
Function \(f \colon \mathbb{R} \to \mathbb{R}\) defined by \(f(x) = 1 + 2x\) is nonlinear
Proof
Take \(\alpha = \beta = x = y = 1\)
Then
\(f(\alpha x + \beta y) = f(2) = 5\)
But \(\alpha f(x) + \beta f(y) = 3 + 3 = 6\)
This kind of function is called an affine function
Fact
If \(T \colon \mathbb{R}^K \to \mathbb{R}^N\) is a linear mapping and \(x_1,\ldots, x_J\) are vectors in \(\mathbb{R}^K\), then for any linear combination we have
Proof
Proof for \(J=3\): Applying the def of linearity twice,
Fact
If \(T \colon \mathbb{R}^K \to \mathbb{R}^N\) is a linear mapping, then
Here \(e_k\) is the \(k\)-th canonical basis vector in \(\mathbb{R}^K\)
note that \(V = \{Te_1, \ldots, Te_K\}\) is the set of columns of the matrix representation of \(T\)
Proof
Any \(x \in \mathbb{R}^K\) can be expressed as \(\sum_{k=1}^K \alpha_k e_k\)
Hence \(\mathrm{rng}(T)\) is the set of all points of the form
as we vary \(\alpha_1, \ldots, \alpha_K\) over all combinations
This coincides with the definition of \(\mathrm{span}(V)\)
Example
Let \(T \colon \mathbb{R}^2 \to \mathbb{R}^2\) be defined by
Then
Exercise: Show that \(V = \{Te_1, Te_2\}\) is linearly independent
We conclude that the range of \(T\) is all of \(\mathbb{R}^2\) (why?)
Definition
The null space or kernel of linear mapping \(T \colon \mathbb{R}^K \to \mathbb{R}^N\) is
Linearity and Bijections#
Recall that an arbitrary function can be
one-to-one (injections)
onto (surjections)
both (bijections)
neither
For linear functions from \(\mathbb{R}^N\) to \(\mathbb{R}^N\), the first three are all equivalent!
In particular,
Fact
If \(T\) is a linear function from \(\mathbb{R}^N\) to \(\mathbb{R}^N\) then all of the following are equivalent:
\(T\) is a bijection
\(T\) is onto/surjective
\(T\) is one-to-one/injective
\(\mathrm{kernel}(T) = \{ 0 \}\)
The set of vectors \(V = \{Te_1, \ldots, Te_N\}\) is linearly independent
Definition
If any one of the above equivalent conditions is true, then \(T\) is called nonsingular
Proof
Proof that \(T\) onto \(\iff\) \(V = \{Te_1, \ldots, Te_N\}\) is linearly independent
Recall that for any linear mapping \(T\) we have \(\mathrm{rng}(T) = \mathrm{span}(V)\)
Using this fact and the definitions,
(We saw that \(N\) vectors span \(\mathbb{R}^N\) iff linearly indepenent)
Exercise: rest of proof
Fact
If \(T \colon \mathbb{R}^N \to \mathbb{R}^N\) is nonsingular then so is \(T^{-1}\).
Proof
Exercise: prove this statement
Mappings Across Different Dimensions#
Remember that the above results apply to mappings from \(\mathbb{R}^N\) to \(\mathbb{R}^N\)
Things change when we look at linear mappings across dimensions
The general rules for linear mappings are
Mappings from lower to higher dimensions cannot be onto
Mappings from higher to lower dimensions cannot be one-to-one
In either case they cannot be bijections
Fact
For a linear mapping \(T\) from \(\mathbb{R}^K \to \mathbb{R}^N\), the following statements are true:
If \(K < N\) then \(T\) is not onto
If \(K > N\) then \(T\) is not one-to-one
Proof
Proof of part 1: Let \(K < N\) and let \(T \colon \mathbb{R}^K \to \mathbb{R}^N\) be linear
Letting \(V = \{Te_1, \ldots, Te_K\}\), we have
Hence \(T\) is not onto
Proof of part 2: \(K > N\) \(\implies\) \(T\) is not one-to-one
Suppose to the contrary that \(T\) is one-to-one
Let \(\alpha_1, \ldots, \alpha_K\) be a collection of vectors such that
We have shown that \(\{Te_1, \ldots, Te_K\}\) is linearly independent
But then \(\mathbb{R}^N\) contains a linearly independent set with \(K > N\) vectors — contradiction
Example
Cost function \(c(k, \ell) = rk + w\ell\) cannot be one-to-one
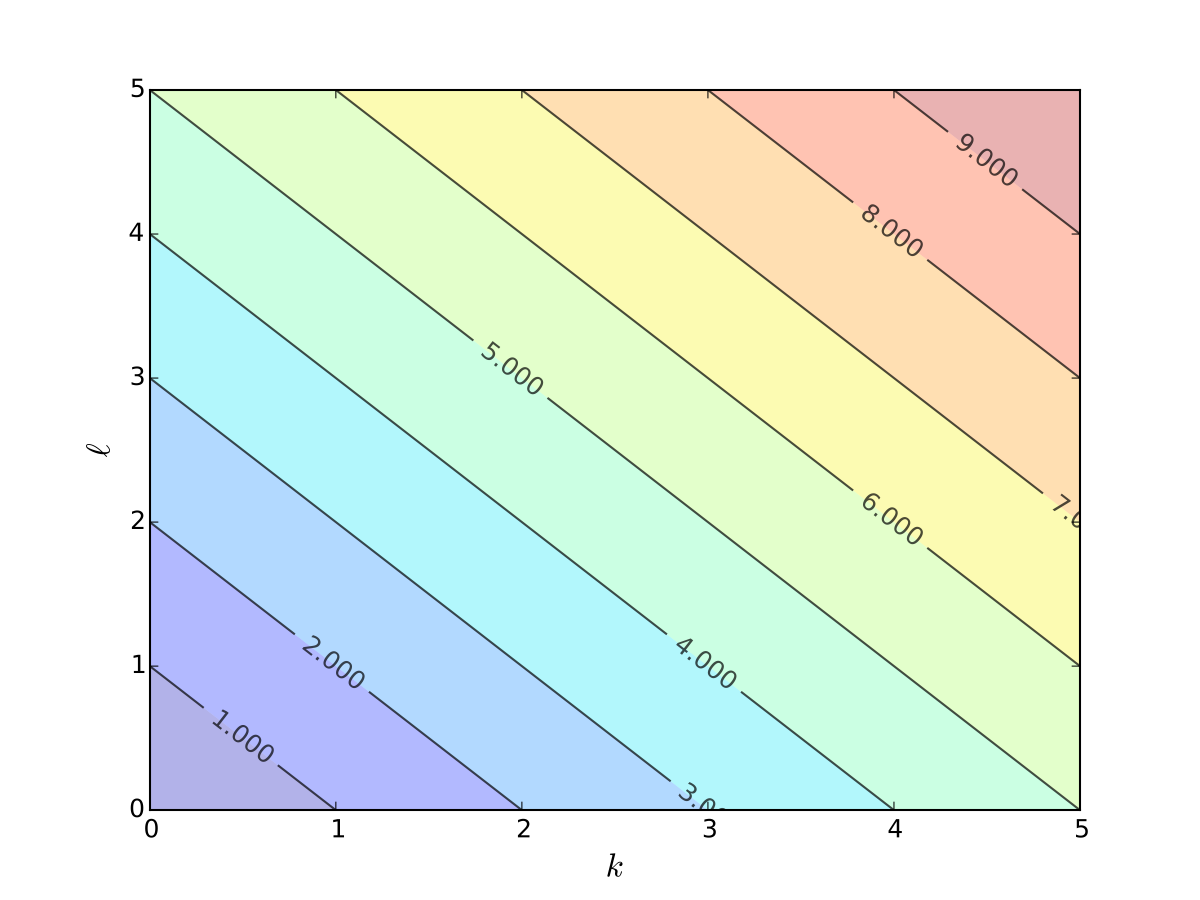
Matrices as Mappings#
Any \(N \times K\) matrix \(A\) can be thought of as a function \(x \mapsto A x\)
In \(A x\) the \(x\) is understood to be a column vector
It turns out that every such mapping is linear!
To see this fix \(N \times K\) matrix \(A\) and let \(T\) be defined by
Pick any \(x\), \(y\) in \(\mathbb{R}^K\), and any scalars \(\alpha\) and \(\beta\)
The rules of matrix arithmetic tell us that
So matrices make linear functions
How about examples of linear functions that don’t involve matrices?
There are none!
Fact
If \(T \colon \mathbb{R}^K \to \mathbb{R}^N\) then
Proof
Just above we showed the \(\Longleftarrow\) part
Let’s show the \(\implies\) part
Let \(T \colon \mathbb{R}^K \to \mathbb{R}^N\) be linear
We aim to construct an \(N \times K\) matrix \(A\) such that
As usual, let \(e_k\) be the \(k\)-th canonical basis vector in \(\mathbb{R}^K\)
Define a matrix \(A\) by \(\mathrm{col}_k(A) = Te_k\)
Pick any \(x = (x_1, \ldots, x_K) \in \mathbb{R}^K\)
By linearity we have
Matrix Product as Composition#
Fact
Let
\(A\) be \(N \times K\) and \(B\) be \(K \times M\)
\(T \colon \mathbb{R}^K \to \mathbb{R}^N\) be the linear mapping \(Tx = Ax\)
\(U \colon \mathbb{R}^M \to \mathbb{R}^K\) be the linear mapping \(Ux = Bx\)
The matrix product \(A B\) corresponds exactly to the composition of \(T\) and \(U\)
Proof
This helps us understand a few things
For example, let
\(A\) be \(N \times K\) and \(B\) be \(J \times M\)
\(T \colon \mathbb{R}^K \to \mathbb{R}^N\) be the linear mapping \(Tx = Ax\)
\(U \colon \mathbb{R}^M \to \mathbb{R}^J\) be the linear mapping \(Ux = Bx\)
Then \(A B\) is only defined when \(K = J\)
This is because \(A B\) corresponds to \(T \circ U\)
But for \(T \circ U\) to be well defined we need \(K = J\)
Then \(U\) mappings \(\mathbb{R}^M\) to \(\mathbb{R}^K\) and \(T\) mappings \(\mathbb{R}^K\) to \(\mathbb{R}^N\)
Column Space#
Definition
Let \(A\) be an \(N \times K\) matrix.
The column space of \(A\) is defined as the span of its columns
Equivalently,
This is exactly the range of the associated linear mapping
\(T \colon \mathbb{R}^K \to \mathbb{R}^N\) defined by \(T x = A x\)
Example
If
then the span is all linear combinations
These columns are linearly independent (shown earlier)
Hence the column space is all of \(\mathbb{R}^2\) (why?)
Exercise: Show that the column space of any \(N \times K\) matrix is a linear subspace of \(\mathbb{R}^N\)
Rank#
Equivalent questions
How large is the range of the linear mapping \(T x = A x\)?
How large is the column space of \(A\)?
The obvious measure of size for a linear subspace is its dimension
Definition
The dimension of \(\mathrm{span}(A)\) is known as the rank of \(A\)
Because \(\mathrm{span}(A)\) is the span of \(K\) vectors, we have
Definition
\(A\) is said to have full column rank if
Fact
For any matrix \(A\), the following statements are equivalent:
\(A\) is of full column rank
The columns of \(A\) are linearly independent
If \(A x = 0\), then \(x = 0\)
Exercise: Check this, recalling that
import numpy as np
A = [[2.0, 1.0],
[6.5, 3.0]]
print(f'Rank = {np.linalg.matrix_rank(A)}')
A = [[2.0, 1.0],
[6.0, 3.0]]
print(f'Rank = {np.linalg.matrix_rank(A)}')
Rank = 2
Rank = 1
Systems of Linear Equations#
Let’s look at solving linear equations such as \(A x = b\) where \(A\) is a square matrix
Take \(N \times N\) matrix \(A\) and \(N \times 1\) vector \(b\) as given
Search for an \(N \times 1\) solution \(x\)
But does such a solution exist? If so is it unique?
The best way to think about this is to consider the corresponding linear mapping
Equivalent:
\(A x = b\) has a unique solution \(x\) for any given \(b\)
\(T x = b\) has a unique solution \(x\) for any given \(b\)
\(T\) is a bijection
We already have conditions for linear mappings to be bijections
Just need to translate these into the matrix setting
Recall that \(T\) called nonsingular if \(T\) is a linear bijection
Definition
We say that \(A\) is nonsingular if \(T: x \to Ax\) is nonsingular
Equivalent:
\(x \mapsto A x\) is a bijection from \(\mathbb{R}^N\) to \(\mathbb{R}^N\)
We now list equivalent conditions for nonsingularity
Fact
Let \(A\) be an \(N \times N\) matrix
All of the following conditions are equivalent
\(A\) is nonsingular
The columns of \(A\) are linearly independent
\(\mathrm{rank}(A) = N\)
\(\mathrm{span}(A) = \mathbb{R}^N\)
If \(A x = A y\), then \(x = y\)
If \(A x = 0\), then \(x = 0\)
For each \(b \in \mathbb{R}^N\), the equation \(A x = b\) has a solution
For each \(b \in \mathbb{R}^N\), the equation \(A x = b\) has a unique solution
All equivalent ways of saying that \(Tx = A x\) is a bijection!
Example
For condition 5 the equivalence is:
\(A x = A y\), then \(x = y\)
\(\iff\)
\(T x = T y\), then \(x = y\)
\(\iff\)
\(T\) is one-to-one
\(\iff\)
Since \(T\) is a linear mapping from \(\mathbb{R}^N\) to \(\mathbb{R}^N\),
\(T\) is a bijection
Example
For condition 6 the equivalence is:
if \(A x = 0\), then \(x = 0\)
\(\iff\)
\(\{x: Ax = 0\} = \{0\}\)
\(\iff\)
\(\{x: Tx = 0\} = \{0\}\)
\(\iff\)
\(\ker{T}=\{0\}\)
\(\iff\)
Since \(T\) is a linear mapping from \(\mathbb{R}^N\) to \(\mathbb{R}^N\),
\(T\) is a bijection
Example
For condition 7 the equivalence is:
for each \(b\in\mathbb{R}^N\), the equation \(Ax = b\) has a solution
\(\iff\)
every \(b\in\mathbb{R}^N\) has an \(x\) such that \(Ax = b\)
\(\iff\)
every \(b\in\mathbb{R}^N\) has an \(x\) such that \(Tx = b\)
\(\iff\)
\(T is onto/surjection\)
\(\iff\)
Since \(T\) is a linear mapping from \(\mathbb{R}^N\) to \(\mathbb{R}^N\),
\(T\) is a bijection
Example
Now consider condition 2: \
The columns of \(A\) are linearly independent.
Let \(e_j\) be the \(j\)-th canonical basis vector in \(\mathbb{R}^N\).
Observe that \(Ae_j = \mathrm{col}_j(A)\) \(\implies\) \(Te_j = \mathrm{col}_j(A)\) \(\implies\) \(V = \{T e_1, \ldots, Te_N\} =\) columns of \(A\), and \(V\) is linearly independent if and only if \(T\) is a bijection
Example
Consider a one good linear market system
Treating \(q\) and \(p\) as the unknowns, let’s write in matrix form as
A unique solution exists whenever the columns are linearly independent
so \((b, -d)\) is not a scalar multiple of \(1\) \(\iff\) \(b \ne -d\)
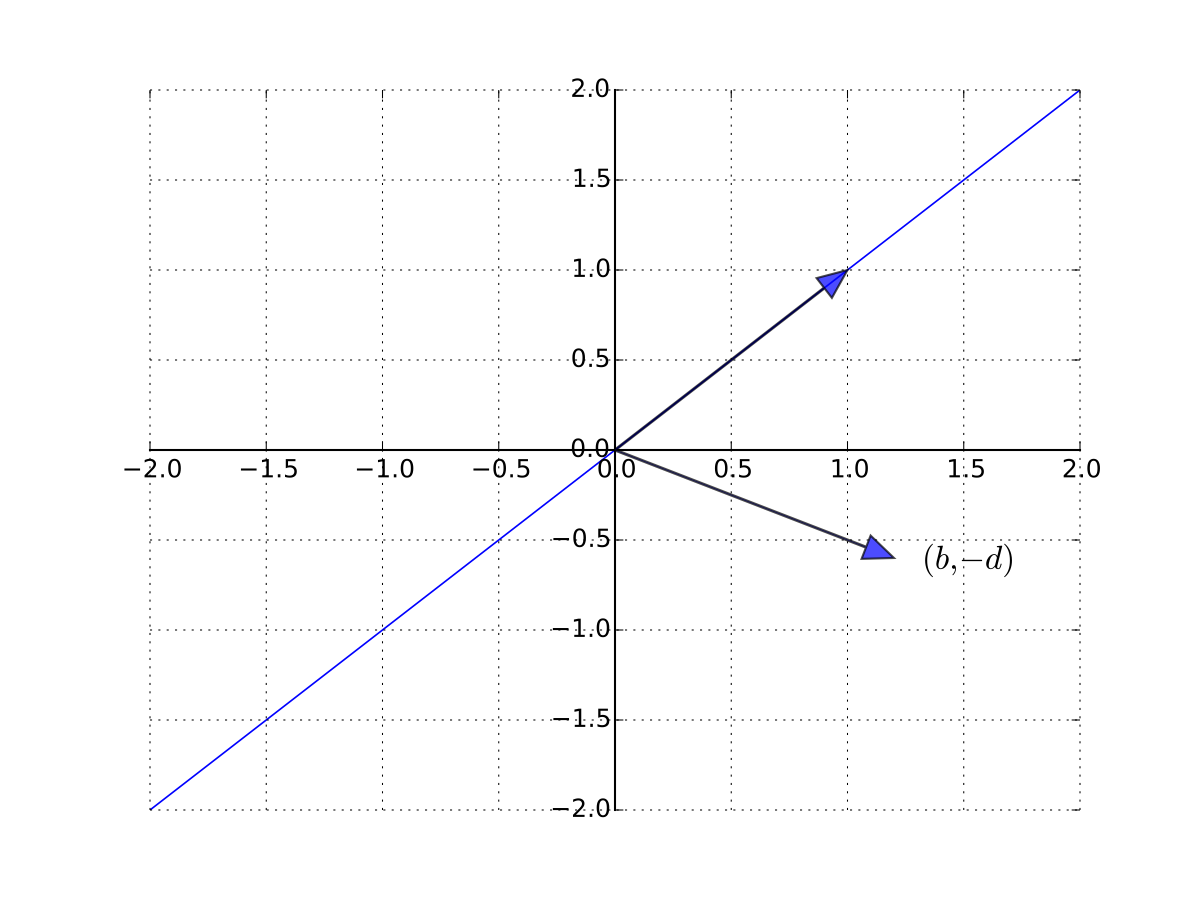
Fig. 63 \((b, -d)\) is not a scalar multiple of \(1\)#
Example
Recall in the introduction we try to solve the system \(A x = b\) of this form
The problem is that \(A\) is singular (not nonsingular)
In particular, \(\mathrm{col}_3(A) = 2 \mathrm{col}_2(A)\)
Definition
Given square matrix \(A\), suppose \(\exists\) square matrix \(B\) such that
Then
\(B\) is called the inverse of \(A\), and written \(A^{-1}\)
\(A\) is called invertible
Fact
A square matrix \(A\) is nonsingular if and only if it is invertible
\(A^{-1}\) is just the matrix corresponding to the linear mapping \(T^{-1}\)
Fact
Given nonsingular \(N \times N\) matrix \(A\) and \(b \in \mathbb{R}^N\), the unique solution to \(A x = b\) is given by
Proof
Since \(A\) is nonsingular we already know any solution is unique
\(T\) is a bijection, and hence one-to-one
if \(A x = A y = b\) then \(x = y\)
To show that \(x_b\) is indeed a solution we need to show that \(A x_b = b\)
To see this, observe that
Fact
In the \(2 \times 2\) case, the inverse has the form
Example
Fact
If \(A\) is nonsingular and \(\alpha \ne 0\), then
\(A^{-1}\) is nonsingular and \((A^{-1})^{-1} = A\)
\(\alpha A\) is nonsingular and \((\alpha A)^{-1} = \alpha^{-1} A^{-1}\)
Proof
Proof of part 2:
It suffices to show that \(\alpha^{-1} A^{-1}\) is the right inverse of \(\alpha A\)
This is true because
Fact
If \(A\) and \(B\) are \(N \times N\) and nonsingular then
\(A B\) is also nonsingular
\((A B)^{-1} = B^{-1} A^{-1}\)
Proof
Proof I: Let \(T\) and \(U\) be the linear mappings corresponding to \(A\) and \(B\)
Recall that
\(T \circ U\) is the linear mapping corresponding to \(A B\)
Compositions of linear mappings are linear
Compositions of bijections are bijections
Hence \(T \circ U\) is a linear bijection with \((T \circ U)^{-1} = U^{-1} \circ T^{-1}\)
That is, \(AB\) is nonsingular with inverse \(B^{-1} A^{-1}\)
Proof II:
A different proof that \(A B\) is nonsingular with inverse \(B^{-1} A^{-1}\)
Suffices to show that \(B^{-1} A^{-1}\) is the right inverse of \(A B\)
To see this, observe that
Hence \(B^{-1} A^{-1}\) is a right inverse as claimed
Singular case#
Example
The matrix \(A\) with columns
is singular (\(a_3 = - a_2\))
Its column space \(\mathrm{span}(A)\) is just a plane in \(\mathbb{R}^2\)
Recall \(b \in \mathrm{span}(A)\)
\(\iff\) \(\exists \, x_1, \ldots, x_N\) such that \(\sum_{k=1}^N x_k \mathrm{col}_k(A) = b\)
\(\iff\) \(\exists \, x\) such that \(A x = b\)
Thus if \(b\) is not in this plane then \(A x = b\) has no solution
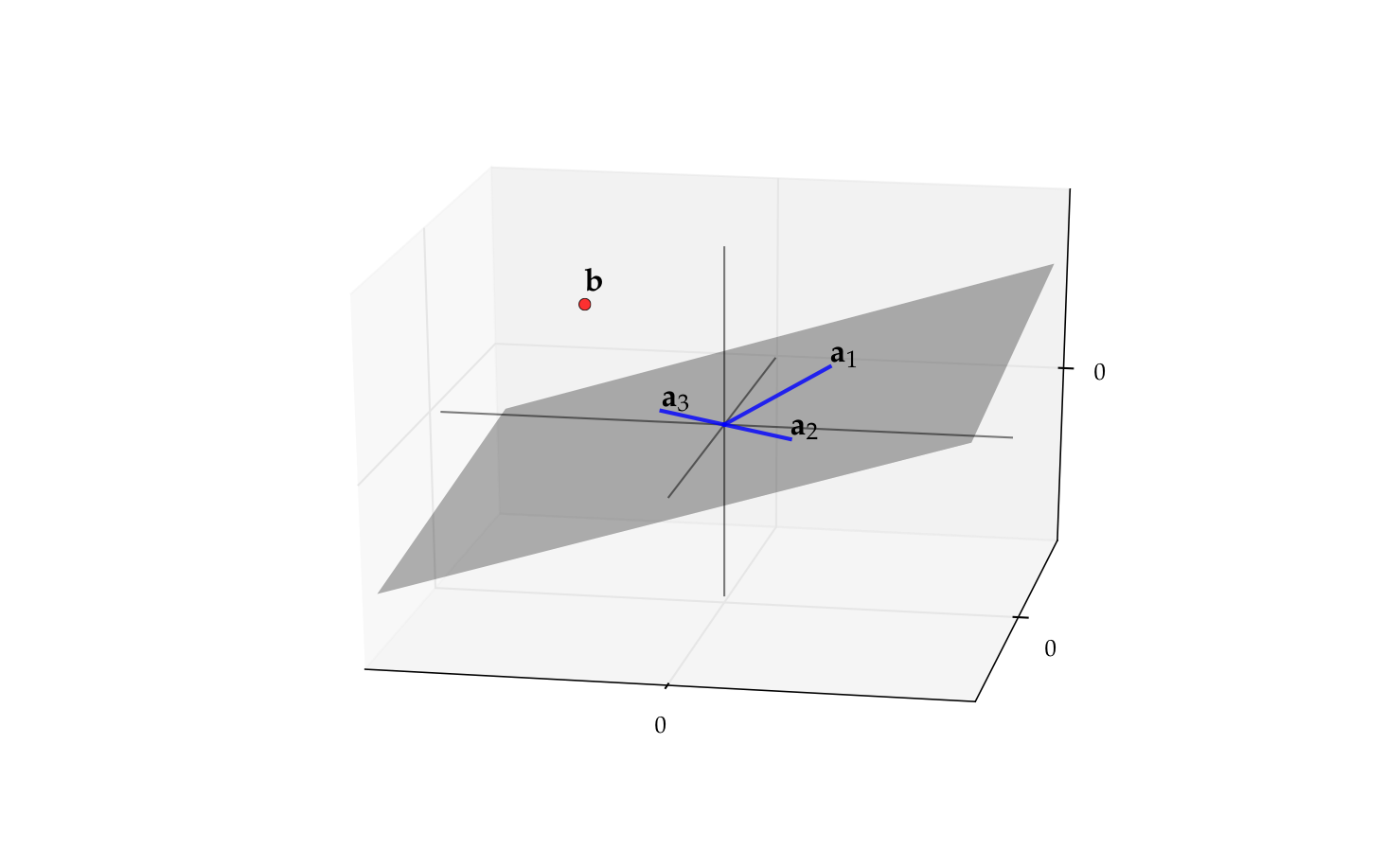
Fig. 64 The vector \(b\) is not in \(\mathrm{span}(A)\)#
Fact
If \(A\) is a singular matrix and \(A x = b\) has a solution then it has an infinity (in fact a continuum) of solutions
Proof
Let \(A\) be singular and let \(x\) be a solution
Since \(A\) is singular there exists a nonzero \(y\) with \(A y = 0\)
But then \(\alpha y + x\) is also a solution for any \(\alpha \in \mathbb{R}\) because
References and reading#
References
[Simon and Blume, 1994]: 6.1, 6.2, 10.1, 10.2, 10.3, 10.4, 10.5, 10.6, 11, 16, 23.7, 23.8
[Sundaram, 1996]: Appendix C.1, C.2
Further reading and self-learning
Excellent visualizations of concepts covered in this lecture, strongly recommended for further study 3Blue1Brown: Essence of linear algebra